旋转目标检测(一)-RRPN
旋转目标检测(一)-RRPN
简介
- 论文题目 : Arbitrary-Oriented Scene Text Detection via Rotation Proposals
- 论文地址 : https://arxiv.org/abs/1703.01086
- 代码实现 : https://github.com/mjq11302010044/RRPN

自然场景文本检测存在的困难:光照不均,模糊,透视畸变,文本不定向等等
前人提出的使用分段网络(如完全卷积网络[FCN])生成文本预测图,需要几个后处理步骤来生成具有所需方向的最终文本区域建议,通常非常耗时。
作者提出了基于旋转候选框实现任意方向的场景文本检测,简称RRPN,其思想沿用的是目标检测中的RPN,在其基础上增加了旋转角度信息。最后在三个数据集(MSRA-TD500, ICDAR2013,ICDAR2015)进行了测试,发现它比以前的方法准确而且更有效。
Idea
- 与先前基于分割的框架不同,作者提出了基于候选框的不定向文本检测,使得候选框可以更好地适应文本区域,可以更好地修正长文本区域
- 作者将新提出的RROI池化层和旋转候选框的学习加入到基于候选框区域的结构当中,与传统的基于分割的文本检测框架相比,确保了文本检测的计算效率
- 作者提出了任意方向选择候选框的新的修正方法(refinement),以提高任意文本检测的性能。
实现
网络结构-RRPN框架
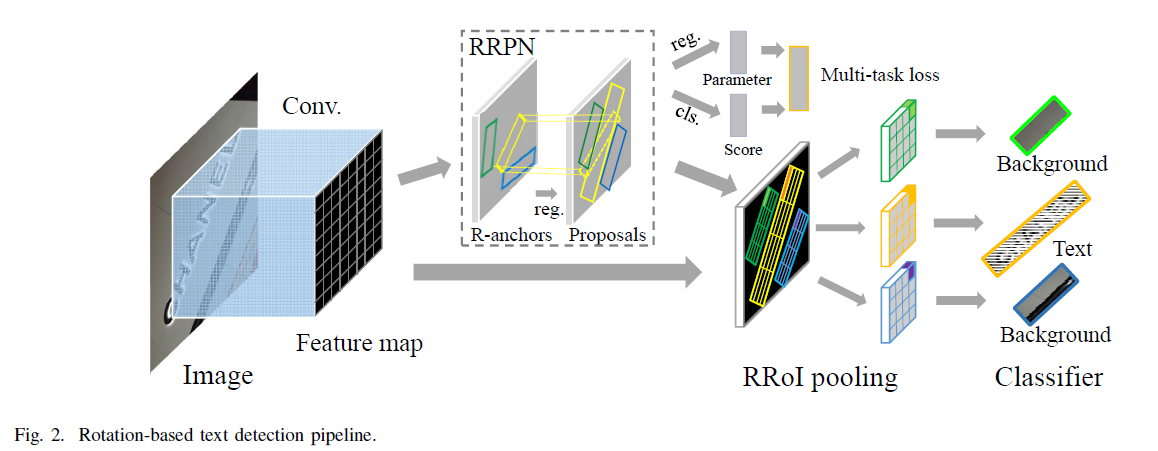
RRPN沿用了Faster-RCNN中的RPN的思想(即使用其来生成候选区域),并在此基础上进行了改进,提出了基于旋转候选网络区域(RRPN).整个网络结构和Faster-RCNN非常相似,RRPN也是分成并行两路:一路用于预测类别,另一路用于回归旋转矩形框。
具体步骤如下:
- 前端使用非常经典的 VGG16 作为主干特征提取网络
- 中间采用RRPN主要是用于生成带倾斜角的候选区域,该层输出包括候选框的类别和旋转矩形框的回归
- 通过RRoI Pooling将RRPN生成的候选框映射到特征图上,得到最终的文本行检测结果
具体细节
1.Rotated Bounding Box Representation-旋转矩形框的表示
用(x,y,w,h,θ)表示旋转矩形框:其中(x,y)表示几何矩形中心点坐标,h表示矩形框的短边长度,w 表示矩形框的长边,θ表示x正轴与矩形框长边的夹角。
围绕矩阵中心旋转α角后,中心锚点坐标公式:
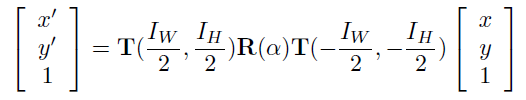
其中 T 是平移矩阵, R 是旋转矩阵。
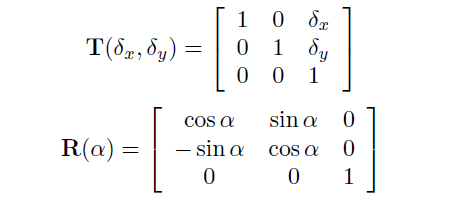
2.Rotation Anchors Strategy-锚点旋转策略
Anchors 就是按照固定比例(长宽、大小)预定义的框,在后续阶段找出Bounding-box位置和大小,是以这些框为基础。
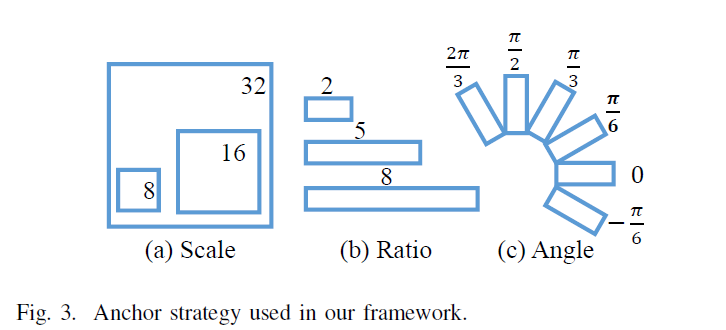
作者提出的锚点R-anchor有三类策略:
- scale 有8,16,32三种,表示文本行的大小
- ratio 有1:2,1:5,1:8三种,表示文本行的宽高比
- angle 有、、、、、六种,表示提议框的旋转角
综上所述,特征图上每个点将生成54个R-anchor(6个方向,3个尺度,3个宽高比)
3.Learning of Rotated Proposal-旋转矩形候选框的学习
RRPN层会生成很对很多的旋转矩形框,那么这些矩形框中有哪些是需要送入网络参与训练呢?
首先作者提出了如何确定它们当中用于作为训练的正、负样本的标准:
- 训练正样本
需要同时满足以下两种条件:
1.其与ground truth的IOU大于0.7
2.其与ground truth的夹角小于
- 训练负样本
满足以下条件之一:
1.其与ground truth的IOU小于0.3
2.其与ground truth的IOU大于0.7,并且与ground truth的夹角大于
- 损失函数
作者采用的是多任务损失函数,总公式如下:
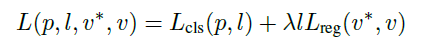
其中分类损失函数Lcls: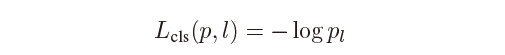
其中回归损失函数Lreg: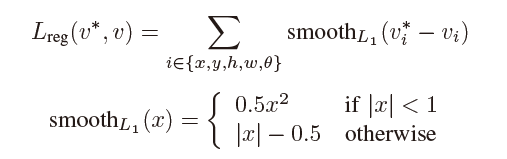
4.Proposal Refinement–候选框修正
倾斜IOU的计算
作者使用的是倾斜的候选框,所以基于水平候选框的IOU计算方法不合适,因此提出了倾斜IOU的计算方法

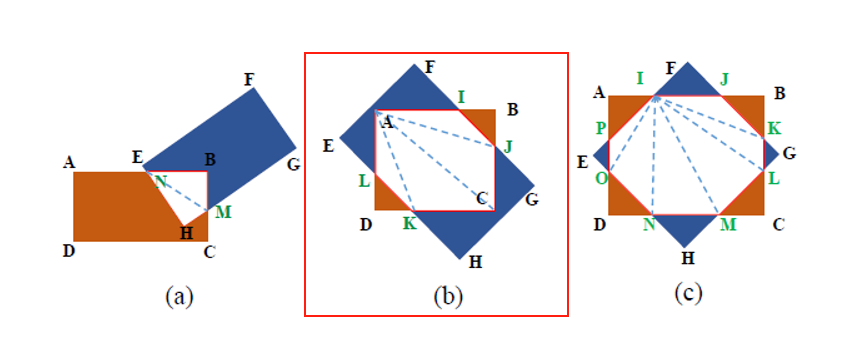
总体思路:将两个矩形的交点进行顺时针排序并连成多边形,然后分割成一个个小三角形计算总面积。
以下图(b)举例子,多边形顺序AIJCKL,分割成三角形AIJ,AJC,ACK,AKL,计算这四个三角形的和。
RROI pooling
针对任意方向的文本,作者提出了旋转ROI池化层.
将高度为h和宽度为w的旋转候选区域平均划分,每个子区域和候选框的方向相同.具体的实现细节如下

实验结果
作者最后在三个数据集(MSRA-TD500, ICDAR2013,ICDAR2015)进行了测试,发现它比以前的方法准确而且更有效。

知识索引
正样本/负样本
正样本是指属于某一类别的样本,反样本是指不属于某一类别的样本。
Intersection over Union - IoU - 交并比
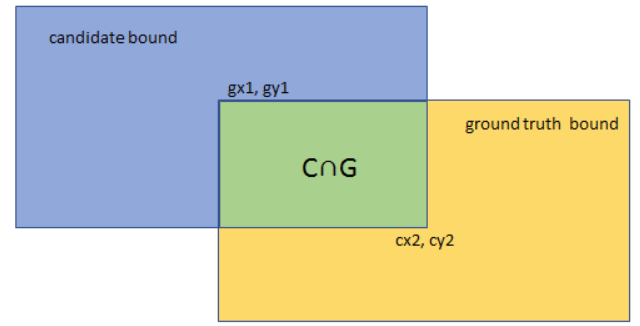
交并比 (Intersection-over-Union,IoU),是候选框(candidate bound) 与 原标记框(ground-truth bounding box)的交叠率,即它们的交集与并集的比值。
一般情况下,0.5 是阈值,用来判断预测的边界框是否正确。如果你希望更严格一点,你可以将 IoU 定得更高,比如说大于 0.6 或者更大的数字。IoU 越高,边界框越精确。
个人反思总结
接触到了许多陌生的概念,读起来感觉有些吃力
(
有时非常搞不懂某一步的意义:
- 为什么要做这一步,作者是怎么想到要这样做的
- 这一步是怎么推导实现的?【突然出现一个公式或是算法,让人感觉摸不着头脑】
),
- 应该先找找比较经典的CV论文看看,打好基础
很多论文之间的思路都具有关联性,只有多看才能真正理解作者的思路
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!