YOLOv1
YOLOv1
Introduction
- 论文题目 : You Only Look Once: Unified, Real-Time Object Detection
- 论文地址 : https://arxiv.org/pdf/1506.02640.pdf
YOLO将物体检测作为回归问题求解。基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别输出。
Idea
[1] YOLO训练和检测均是在一个单独网络中进行。YOLO没有显示地求取region proposal的过程。而rcnn/fast rcnn 采用分离的模块)求取候选框(可能会包含物体的矩形区域),训练过程因此也是分成多个模块进行。
[2]YOLO将物体检测作为一个回归问题进行求解,输入图像经过一次inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。
NetWork
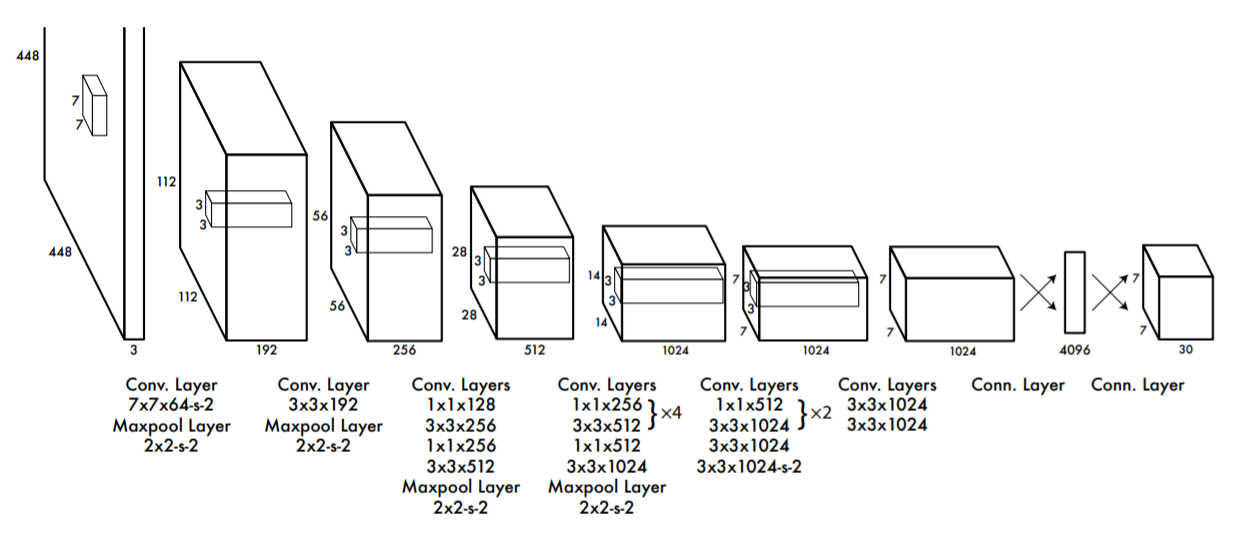
Predicting
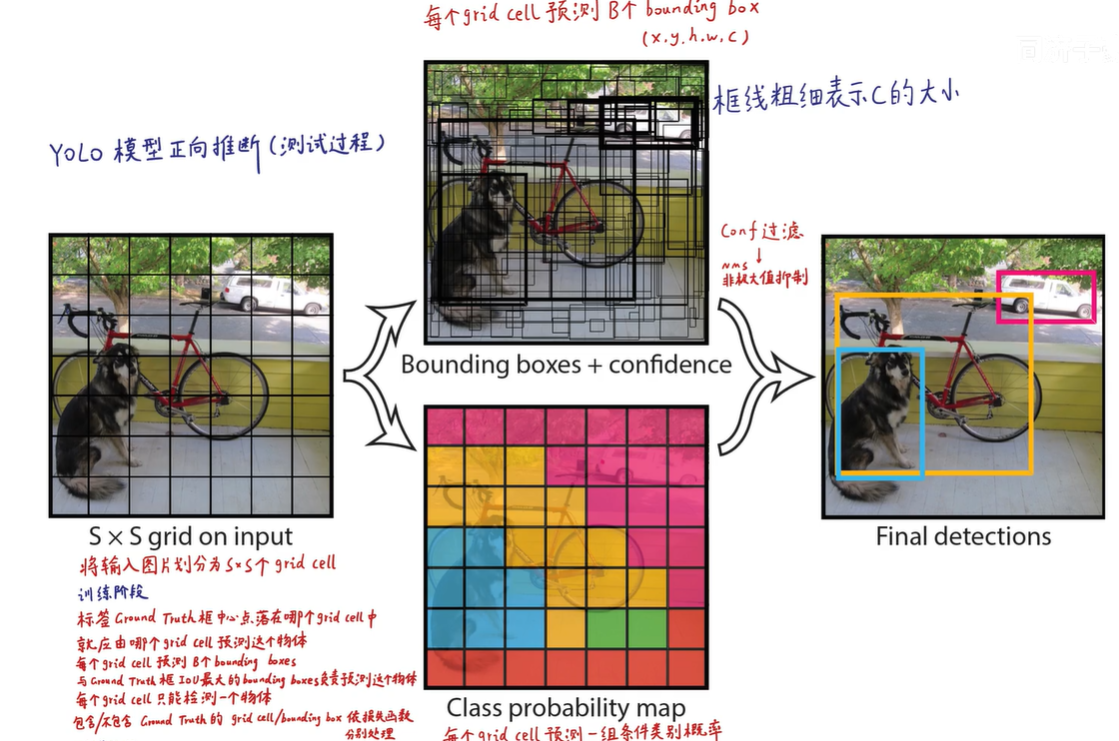

PPT演示 : 地址
把448x448x3的输入图像,进行编码、压缩、处理,经过卷积层,全连接层,最后得到一个7x7x30的张量。
7x7对应的是7x7个Grid Cell,30维由5(第一个BBox参数)、5(第一个BBox参数)、20(假设在该GridCell的条件下,对应的20个类别概率)构成。
全概率=条件本身发生的概率[置信度,Grid Cell在该BBox包含物体的概率]x条件概率[该条件下,20个类别概率]
使用NMS[非极大值抑制]把低置信度和重复的框过滤掉,只保留一个,最终获得目标检测的结果。
Training
深度学习的训练是通过梯度下降和反向传播方法,去迭代更新神经元的权重,来使得Loss函数最小化的过程。

人工标注数据Ground Truth,这个Ground Truth的中心点落在哪个Grid Cell里,就应该由哪个Grid Cell预测出的BBox负责拟合这个Ground Truth。

之前也说到每个Grid Cell预测两个BBox,然后分别计算IOU,选择IOU较大的BBox来负责拟合该Ground Truth,让该BBox最终尽可能逼近Ground Truth。

接下来看损失函数:
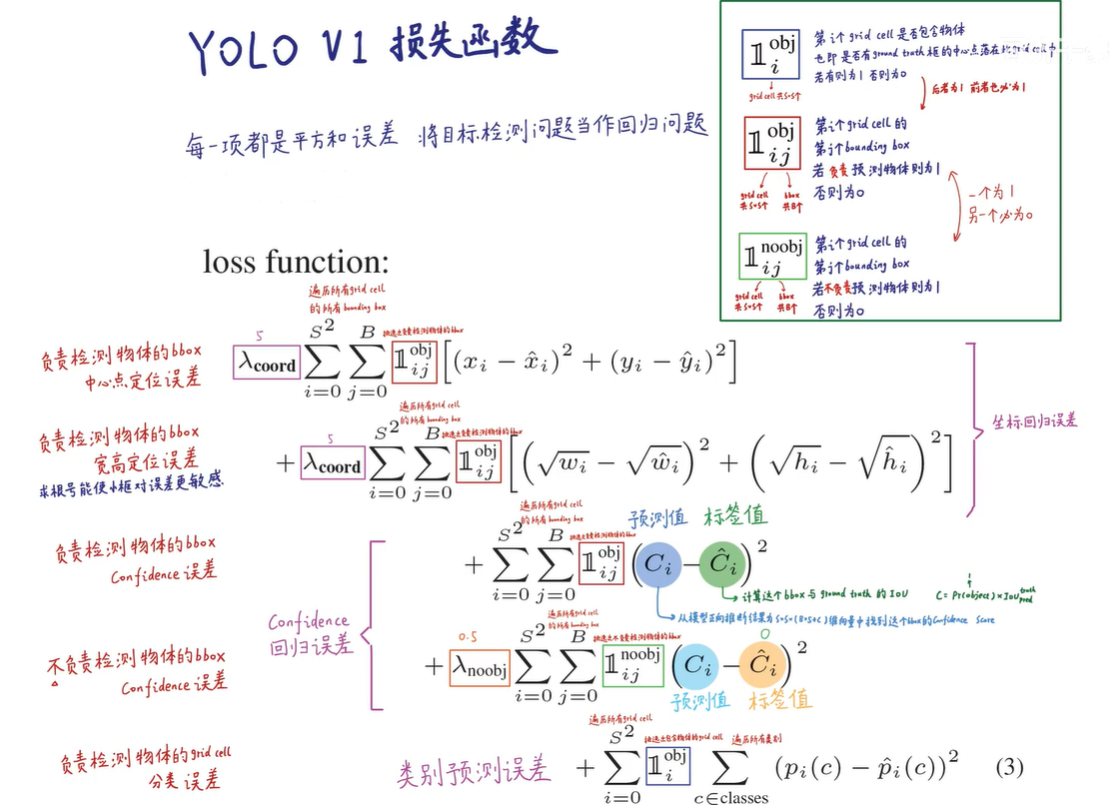
遍历所有Grid Cell中的所有BBox,采用平方和误差。
- 整体分为五个部分,负责检测的BBox的中心点误差、负责检测的BBox的宽高误差、负责检测的BBox的Confidence误差、不负责检测的BBox的Confidence误差、负责检测物体的Grid Cell的分类误差。
- 对于负责检测的BBox的宽高误差,采用求根号能使小框对误差更敏感
- 给予负责检测物体的BBox更高的权重: ,给予不负责检测物体的BBox较低的权重:
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!