系统设计-Ch1-从零到百万用户量,需要考虑哪些问题?
分布式系统架构
1.分层业务与数据库请求
随着用户量的增长,一台服务器是远远不够的,
我们需要多台服务器,把Web/App服务请求和数据库这两类服务请求分离,分离成web server层和database层,使得它们可以独立扩展。
关系型数据库,也称为SQL数据库,以表的形式存储数据,可以通过联接表来在信息之间建立关联或关系。
非关系型数据库称,也为NOSQL数据库,存储方式分为4类:key-value,graph,column,document,通常不支持联接操作(Join operation)。
通常来说,关系型数据库是最佳选择,因为关系型数据库能满足绝大部分需求并且work well。
但在以下情况下,非关系型数据库可能是更好的选择:
- 你的Web/App需要 超低(super-low) 延迟
- 你的数据是非结构化的,或者甚至没有任何有相互关联的数据
- 你只需要序列化和反序列化数据(JSON、XML、YAML等序列化协议)
- 你需要存储海量数据(大数据应用)
垂直扩展(Vertival Scaling)VS水平扩展(Horizontal Scaling)
垂直扩展(scale-up):是指为服务器增加更多的功率(通过升级CPU、RAM等方式提升服务器性能)
水平扩展(scale-out):是指为添加更多台服务器,这些服务器提供相同的功能服务
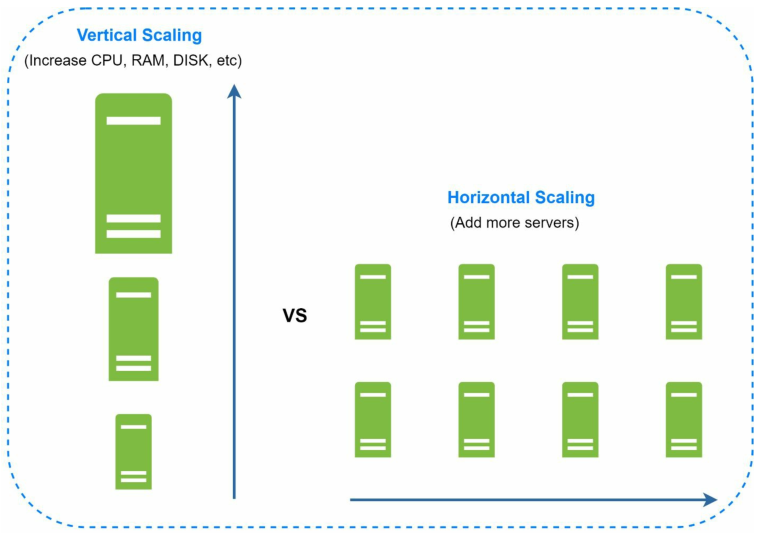
显然,垂直扩展的优势是简单,只需要为服务器升级硬件即可,但是再好的硬件其性能终究有局限----当你全部换成最好的硬件,就没有提升空间了,还有当你升级服务器时,如果你只有一台服务器那就必须停止服务。并且当服务器宕机时,没有故障切换(failover)和冗余(redundancy);相比之下,水平扩展对大规模,高并发应用更加可取,系统水平扩展后也就是我们常听到的分布式系统。
水平扩展具有下优点:
- 更好的性能:多台服务器响应可以应对流量高峰。
- 可靠性:某个节点宕机后,仍然有其它节点工作,很容易解决故障切换的问题。
负载均衡器(Load Balancer)
水平扩展的服务器通过负载均衡器连接,如下图所示:
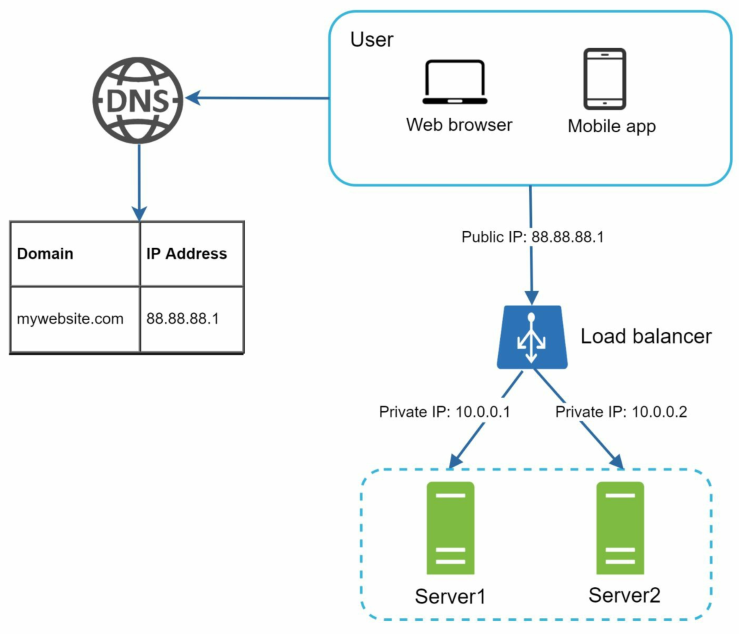
由于负载均衡策略,负载均衡器会均匀分配传入流量到与其关联的服务器(统称为负载均衡集群)中。
- 水平扩展的负载均衡策略(Load-Balancing)是什么?
- 什么是负载均衡器的粘性会话?
数据库复制(Database Replication)
上面是对Web服务器的水平扩展,下面介绍数据库的水平扩展,也就是分布式数据库。
分布式数据库,相比于单节点数据库服务器能克服故障切换(failover)的问题,拥有多个节点的挑战在于数据一致性(data consistency)。如果所有节点在任何时间都是同步的,则系统是线性化的(linearizabile),这是跨多个寄存器的数据一致性的最强保证。跨所有数据库节点同步数据的过程称为复制,我们可以使用多种方案。下面介绍最常见的单主节点复制方案。
单主节点复制(Single-Primary Replication)
单主节点复制方案如下图所示:
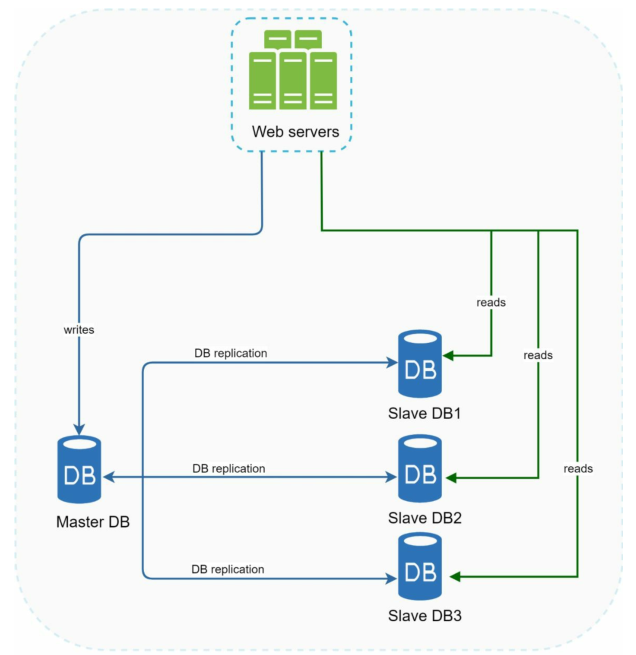
图中的Master DB,即主节点,是唯一能接受写事务(wirte transactions)的节点;而图中多个Slave DB,即从节点,负责处理只读(read-only transactions)事务。拥有单一的事实来源可以让我们避免数据冲突。
数据库分片(Database Sharding)
数据库分片是在多台机器上存储大型数据库的过程。一台计算机或数据库服务器只能存储和处理有限数量的数据。数据库分片通过将数据拆分为更小的块(称为分片)并将其存储在多个数据库服务器上来克服此限制。在任何时候访问数据时,都会使用哈希函数查找相应的分片数据库。
比如下面这种基于user_id分片的数据库,其使用user_id % 4作为哈希函数:
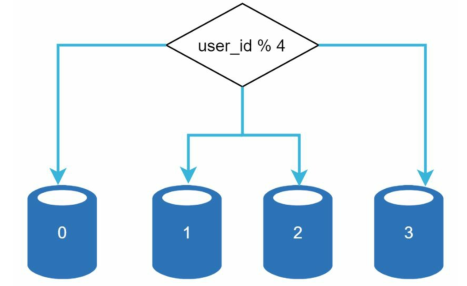
这个分片的哈希函数非常重要,其设计标准就是要使得数据量在分片中均匀分布:
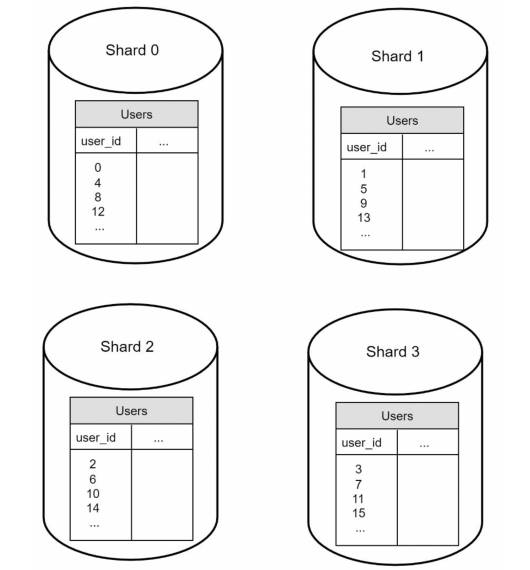
假如说有名人,名人的数据量显然会多于普通人,对这种特定分片的过度访问困难会导致服务器过载,那么就有必要考虑是否需要为每个名人单独分配一个分片。
把负载均衡器和数据库复制都加上,整个系统设计就变成了如下图所示:
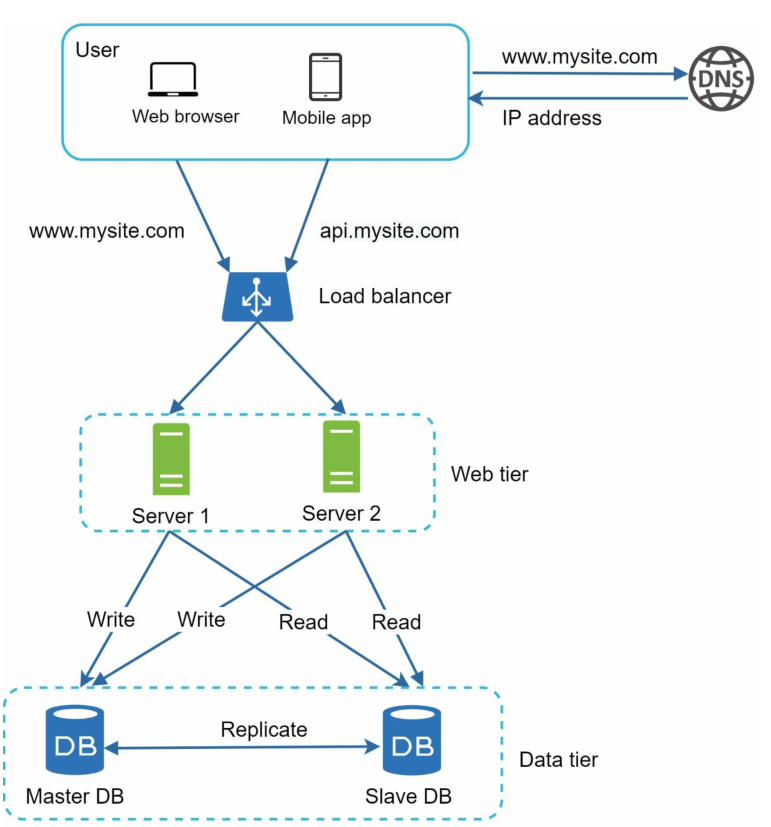
- 用户访问DNS服务器,解析得到的是负载均衡器的IP地址
- 然后用户的Client会和负载均衡器建立连接
- 负载均衡器接受到用户发来的HTTP请求,通过其内置的路由表把HTTP请求转发到真正的Web服务器
- Web服务器在Slave DB中读取用户数据
- Web服务器在Mater DB中更改数据(如果有数据的增删改操作),之后Master数据同步到Salve
2.优化加载/响应时间
现在你已经对web层和data层有了深刻的了解,是时候把目标转向改进加载/响应时间了。
缓存(Cache)
这里的缓存和操作系统中的缓存要达到的目的是一样的:
我们如果频繁的对数据库执行I/O操作,会极大的影响应用程序的性能(因为数据库的I/O往往是其瓶颈)。缓存通过将非常耗时的或频繁访问的响应数据结果存储在内存之中,以便更快处理后续相同的请求。

内容分发网络(Content Delivery Network)
CDN是一个由地理上分散的服务器组成的网络,用于传输静态内容,如image, video, css, javascript等。
简单来说,就是当用户访问网站时,距离用户主机地理位置最近的CDN服务器将提供网站的静态内容。
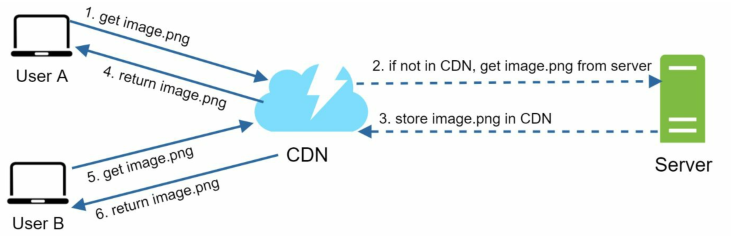
CDN的工作流程非常类似于缓存,不同之处在于其内容的过期时间一般由HTTP头中的Time-to-Live(TTL)决定
CDN通常是由第三方服务商统一提供服务。
添加缓存和内存分发网络后,整个系统设计就变成了如下图所示:
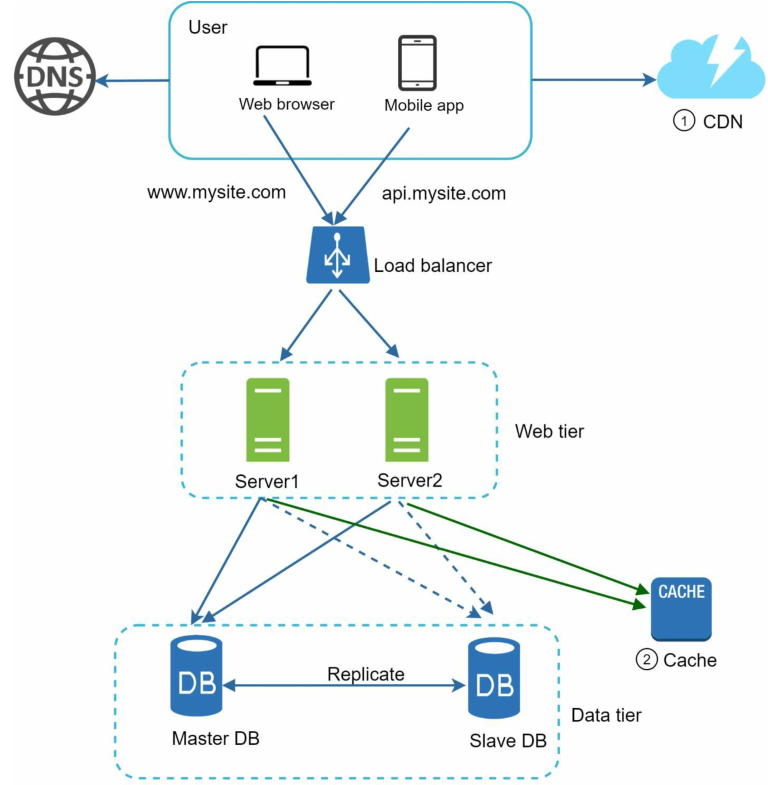
与之前相比有了如下变化:
- 静态内容(如css, javascript, image, vide等)不在由web服务器提供,转为由CDN提供
- 添加了缓存层来减少数据库I/O频率,以减轻数据库负载
3.打造无状态服务器层
状态(State)
web服务器的某些请求需要验证用户身份(如是否登录,是否VIP等),但由于HTTP协议是无状态的协议,web服务器所以并不知道请求是由哪个用户发出的,那么就需要用某个标识来识别具体的用户,这个标识就是session。当第一次创建session的时候,web服务器会在http(s)协议中告诉客户端(同一电脑上不同浏览器被视为不同的客户端)sessoin_id,客户端会在cookie里面记录一个JSESSIONID=session_id,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。
这里的session其实就是一种状态。
在分布式服务器架构上,如果不将状态和服务器分离,会带来一系列问题(如下面的有无状态服务器架构);
一个好的做法是将会话数据存储在数据库(常用NoSQL k-v存储)中(如下面的有无状态服务器架构)。
有状态服务器架构(Stateful Architecture)
有状态服务器会记录从一个请求到下一个请求的客户端状态,其服务器架构如下所示:
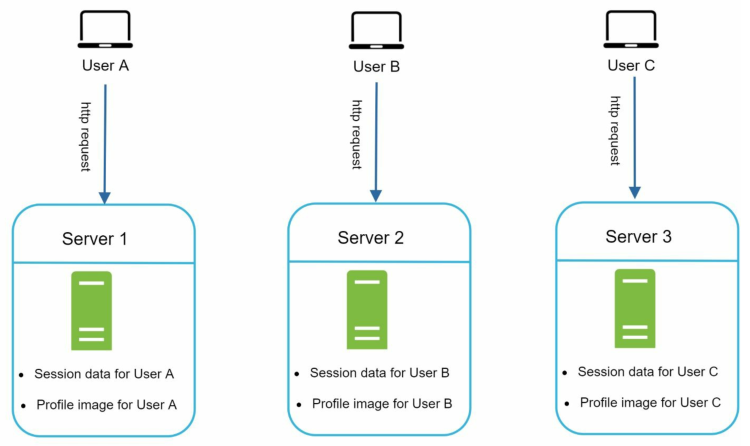
用户 A的session被存储在Server 1中。要对用户 A进行身份验证,必须将http(s)请求路由到Server 1,因为如果向Server 2等其它服务器发送请求,因为其它服务器不包含用户 A的session,身份验证将会失败!
问题的本质在于当server是有状态服务器(Stateful server)时,来自同一客户端的每个请求必须路由到同一服务器。这可以通过负载均衡器中的粘性会话来实现;然而,这无疑增加了开销,并且也会为水平扩展带来困难。
无状态服务器架构(Stateless Architecture)
无状态服务器不会保留任何状态信息,其服务器架构如下所示:
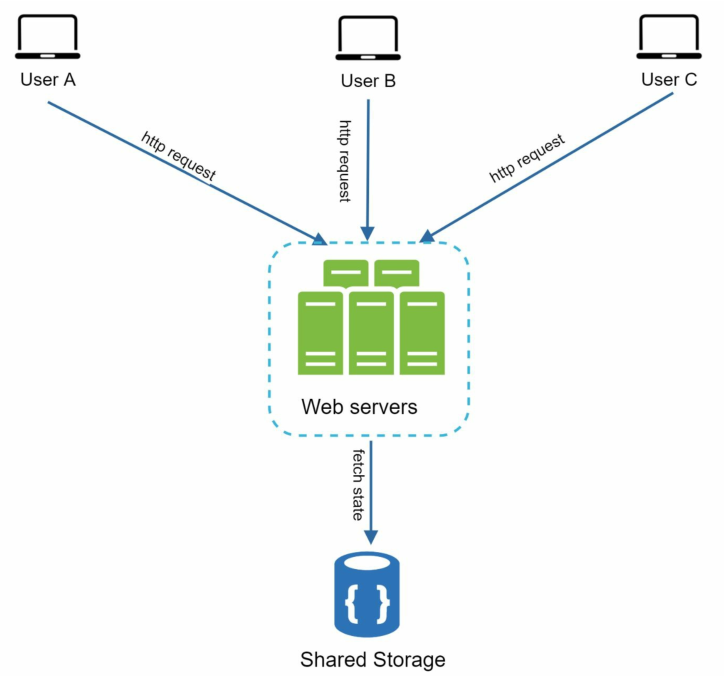
会话数据存储在一个NoSQL数据库中,使得集群中的每个web服务器都能访问数据库中的状态数据。
选择NoSQL数据存储是因为它易于扩展。
现在我们将状态移出web服务器层,并将它们存储在持久化数据存储中,整个系统设计就变成了如下图所示:
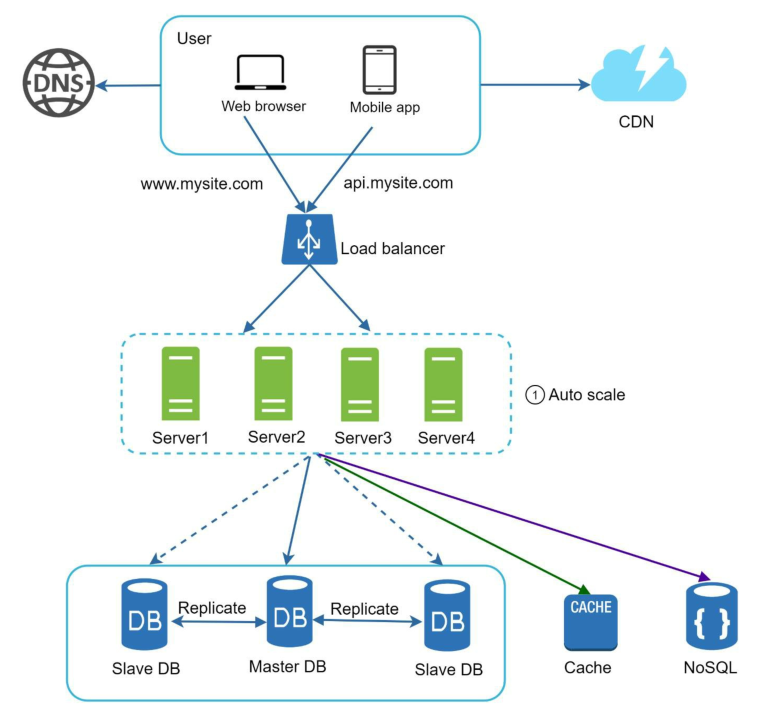
4.建立数据中心
你的网站发展迅速,在国际上吸引了大量用户,为了提高可用性并在更广泛的地理区域提供更好的体验,支持多个数据中心至关重要。
数据中心(Data Center)
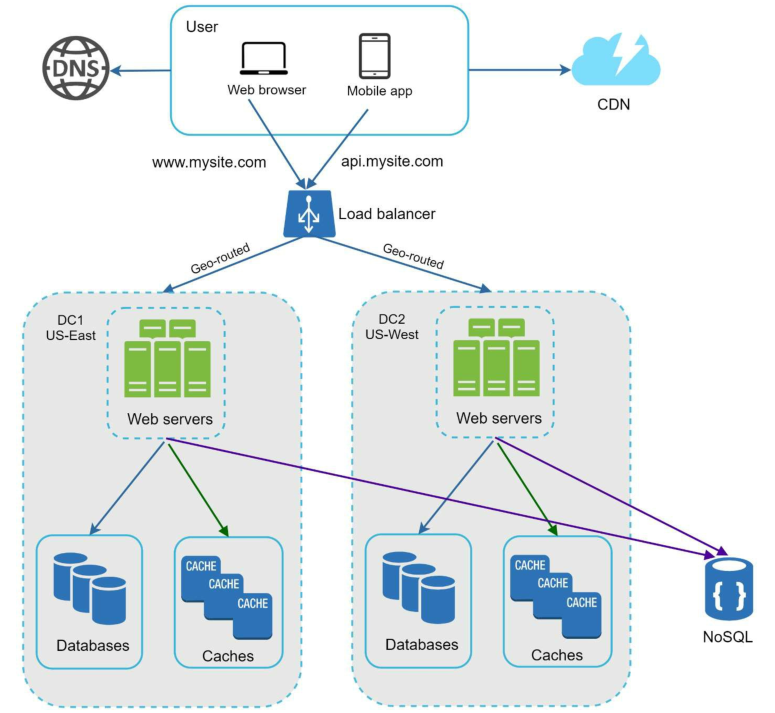
5.解耦系统组件
为了进一步扩展我们的系统,我们需要解耦系统的不同组件,以便它们可以独立扩展。
消息队列(Message queue)
消息队列是一个持久组件,存储在内存中,支持异步通信。它充当缓冲区并分发异步请求。

消息队列的基本架构很简单:
- 输入服务,称为生产者(Producer),创建消息,并将其发布在消息队列中。
- 其它服务,称为消费者(Consumer),连接到队列,并执行消息中定义的操作。
解耦使得消息队列成为构建可扩展程序的首选架构。有了消息队列,当消费者无法处理消息时,生产者可以将消息发布到队列。即使生产者不可用,消费者也可以从队列中读取信息。
日志、指标、自动化(Logging, metrics, automation)
日志、指标、自动化是维护网站/应用程序的好工具(tools)。
日志记录:监控错误日志尤为重要,你可以按服务器级别监视错误日志,也可以聚合到一个集中的服务方便查看
指标:收集不同类型的指标有助于了解业务发展状况和系统的健康情况。
自动化:当系统变得庞大时,自动化工具(构建、测试、部署等)可以显著提高生产力。
解耦以上组件后,整个系统设计就变成了如下图所示:
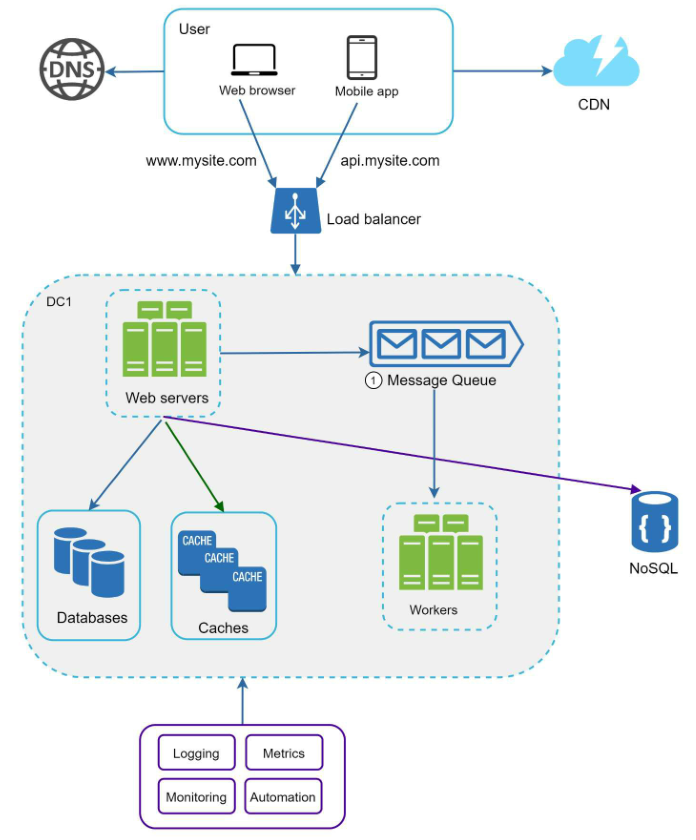
最终系统设计图示
加上数据库分片后,最终整个系统设计就变成了如下图所示:
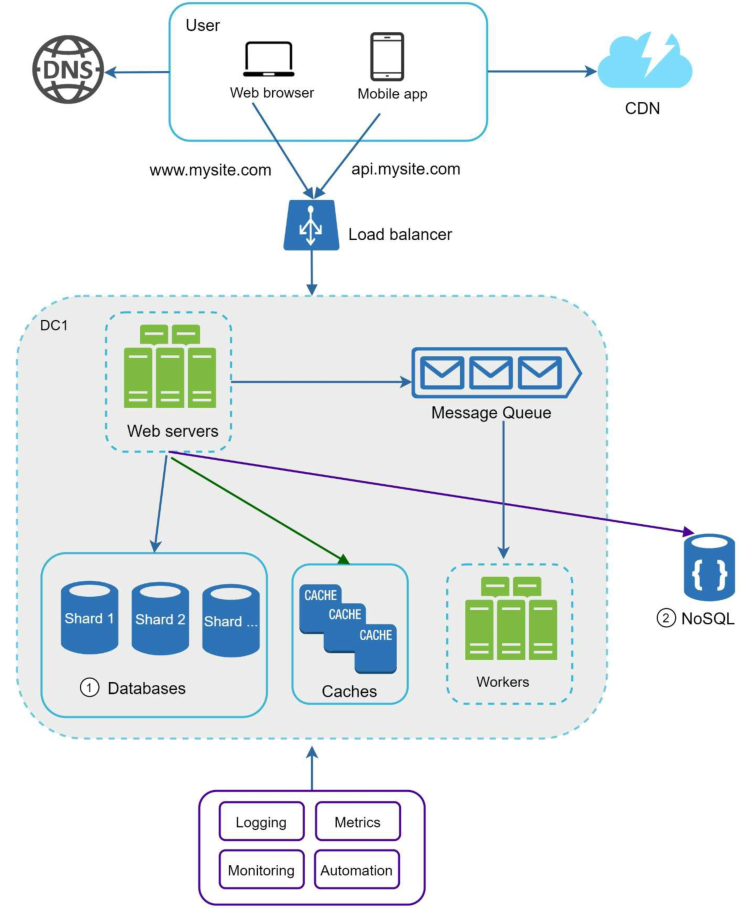
当然上图也并不是最完善、最具体的设计方案,但是通过以上五点,相信你已经对分布式系统设计有了大体的概念和优化思路。
Ref
https://stackoverflow.com/questions/10539129/how-does-replication-work-in-a-distributed-database
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!