系统设计-Ch4-设计一个限流器
设计一个限流器
API Gatway在云服务器中也有配置选项,你可以去了解了解
Step1:Understand the problem and establish design scope
对于”设计一个限流器“这个系统设计话题,我们可以向面试官提出以下问题:
这个限流器是要集成在服务器端,还是做成一个限流器中间件?
限流的规则是什么?是基于UserID、还是基于IP地址还是其它属性?
是要做一个分布式的限流器么,还是单server的就行?
当用户的速率被限制住了,我们应该通知他吗?
Step2:Propose high-level design and get buy-in
下面主要介绍一些实现限流器的限流算法,这是最关键的一步:
限流算法(Algorithm for rate limiting)
令牌桶(Token Bucket)
令牌桶算法的工作原理如下:
- 一个令牌桶有预设的最大容量,令牌会以预设的速率,周期性的放到桶中,一旦桶满了就不会添加令牌
- 设定为每个请求消耗一个令牌("昂贵"的请求可能会消耗更多)
- 如果桶中有足够的令牌,那么从桶中删除请求所需的令牌数量,请求被允许
- 如果桶是空的,那么说明已超过限额,请求被拒绝
下图演示了如何基于令牌桶,设计一个限流器:
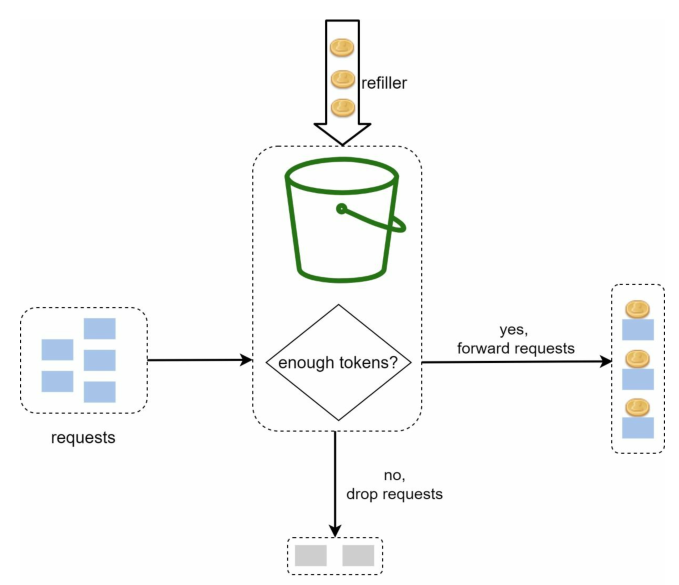
我们总共需要多少个令牌桶呢?这取决于限流规则,来举几个例子:
对于不同功能的API,需要不同的令牌桶。比如:
- 允许用户每秒最多发1篇文章
- 允许用户每秒最多点赞5篇文章
- 允许用户每天最多关注150个用户
以上三个不同功能的API,每个用户就需要3个不同的令牌桶
如果我们需要根据IP地址限流,那么每个IP地址都需要一个令牌桶
如果系统每秒最多允许10000个请求,那么就有必要设计一个让所有请求共享的全局令牌桶
这是一个聪明的算法,只占用很少的空间。但但天真的实现有一个很大的缺陷——一些进程需要不断地重新填充桶。有数百万用户,并且每个重新填充操作都需要写入,这对我们的 Redis 实例来说是不可持续的负载。
我们考虑放弃周期性填充,添加记录最后一次(上次)请求的时间戳。当用户发出请求时,我们获取当前请求的时间戳,由此计算
[上次请求时间戳,当前请求时间戳]这段时间该授予用户多少个令牌。这样每当用户的新请求到来时,才进行令牌桶的填充,可以大大减少填充操作写入次数。这个改进操作并不是完美实现,在分布式限流器架构中会有race contidton,最好的实现方式是redis sorted set或redis + lua脚本。
优点:
- 该算法易于实现
- 高效存储
- 令牌桶允许短时间内的流量爆发,只要还有令牌,请求就可以通过
缺点:
- 算法中的两个超参数是令牌桶的容量和令牌填充速率,要对它们适当调整可能具有挑战性
漏桶(Leaky Bucket)
漏桶算法和令牌桶算法非常相似,其工作原理如下:
- 想象一个底部有个洞的桶,桶底的洞一般是比桶口小很多的
- 这个洞漏水的速率就是我们成功接收请求的速率
- 桶口进水的速率是实际请求发送的速率
- 中间这个桶实际上就是一个先进先出队列(FIFO)
下图演示了如何基于漏桶算法,设计一个限流器:
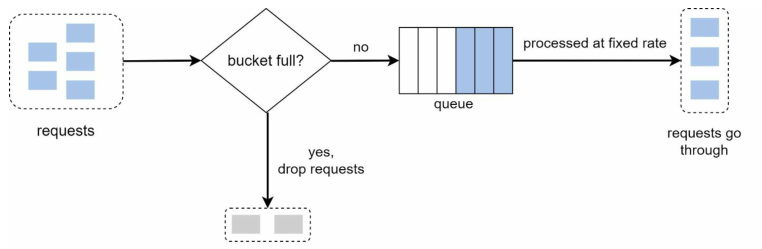
可以看到漏桶算法同样有两个参数:桶的容量(即队列的大小)和漏水速率(处理请求的速率)
优点:
- 在队列大小有限的情况下,内存效率高
- 请求以恒定的速率进行处理,因此适合一些特殊的用例
缺点:
- 突发的流量会使得队列中充满了旧情求,如果不及时处理,将会导致最近的请求速率受到限制
- 算法中有两个超参数,要对它们适当调整可能具有挑战性
固定窗口计数器(Fixed Window Counter)
固定窗口计数器的工作原理如下:
- 该算法划分时间片,每个时间片分配一个计数器,并把时间片看作固定的窗口
- 只关注当前时间片窗口的计数器,每个请求会将当前计数器+1
- 一旦计数器到达预设的阈值,就会丢弃新请求,直到新的时间片窗口开始
下图演示了如何基于固定窗口计数器,设计一个1秒最多3次请求的限流器:
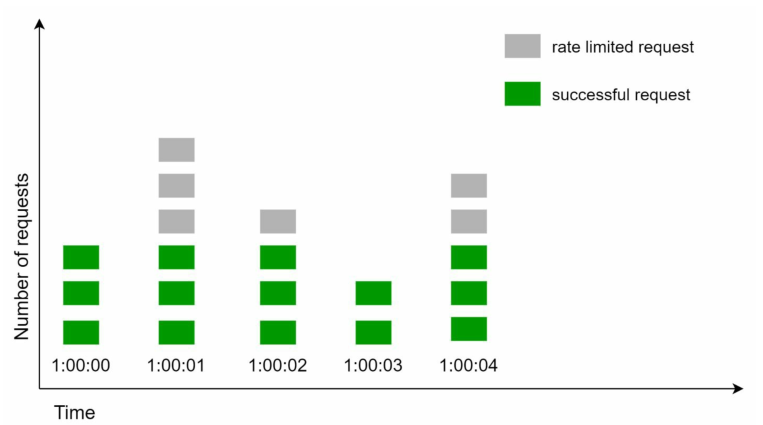
固定窗口计数器的主要问题在于,在时间窗口边缘的流量爆发,可能会超过请求的允许配额,如下图所示:
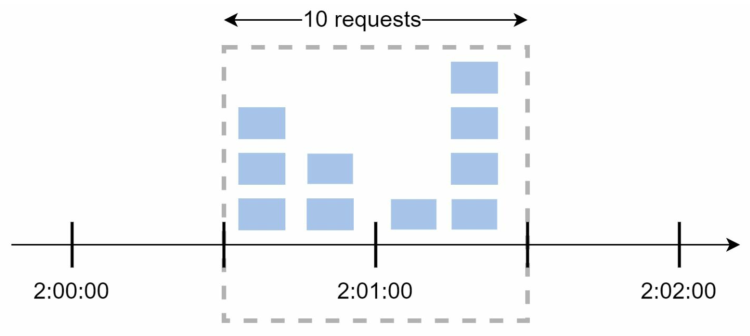
如果系统每分钟最多允许5个请求,并且可用配额在每分钟整点重置,那么如图所示,其实在2:00:30~2:01:30这一分钟内,一共可以允许通过10个请求,是允许请求的两倍。
优点:
- 高效存储
- 易于理解,这应该是最简单基础的限流器设计了
- 在单位时间窗口结束时重置可用配额,这个特性可能适合某些特殊用例
缺点:
- 时间窗口边缘的流量爆发可能会导致超过允许配额
滑动窗口日志(Sliding Window Log)
滑动窗口日志算法可以解决固定窗口计数器算法的边缘流量爆发问题,该算法跟踪请求的时间戳,时间戳通常保存在缓存中(例如redis的sorted set),其工作原理如下:
- 当前时间窗口的边界不再固定,以最新请求的时间戳作为右边界
- 窗口时间段由人为预设,由此可以计算出时间窗口的左边界
- 收到新请求时,计算出当前时间窗口段,删除所有过期的时间戳(不在当前窗口内的),添加当前时间戳
- 加上当前时间戳后,可以得到当前窗口内的总请求次数,如果不超过允许配额,接受请求,否则拒绝请求
可以看到该算法预设参数有2个:窗口时间段,窗口内的允许配额
下图演示了一个窗口时间段为1分钟,窗口允许配额为2,来实现每分钟最多2次请求的限流器:
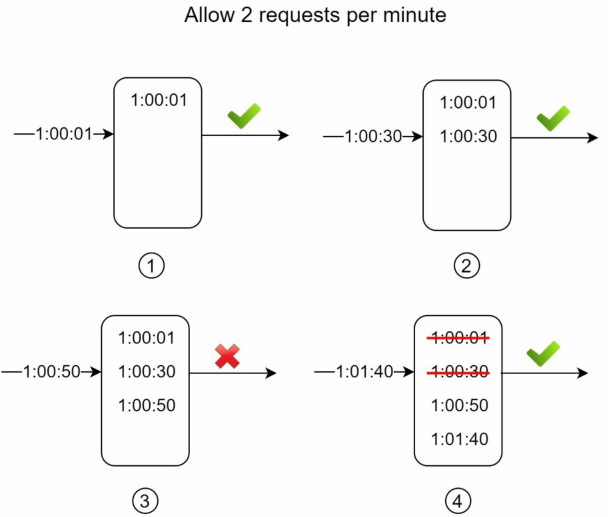
①:日志一开始为空,最新的请求为1:00:01,它被允许了
②:最新的请求为1:00:30,计算得当前时间段为(0:59:30, 1:00:30],当前窗口总请求次数2,允许该请求
③:最新的请求为1:00:50,计算得当前时间段为(0:59:50, 1:00:50],当前窗口总请求次数3,拒绝该请求
③:最新的请求为1:01:40,计算得当前时间段为(1:00:40, 1:00:40],当前窗口总请求次数2,允许该请求
优点:
- 该算法实现的限流器非常准确,在任何滑动窗口中,请求都不会超过速率限制
缺点:
- 该算法消耗大量内存,因为即使请求被拒绝,其时间戳也可能存储在内存中
滑动窗口计数器 (Sliding Winodw Counter)
滑动窗口计数器是一种将固定窗口计数和滑动窗口日志结合的混合方法,该算法可以通过两种不同的方法实现。
这里介绍其中一种实现:
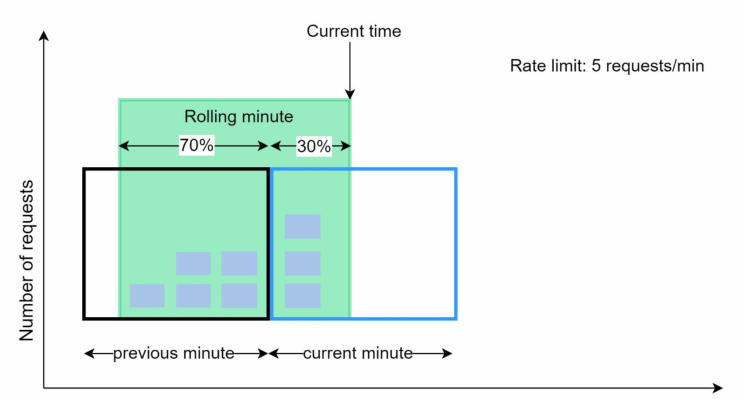
- 该算法划分时间片,每个时间片分配一个计数器,窗口根据最新请求滑动
- 收到新请求时,当前时间片计数器+1,根据新请求的时间戳,计算当前窗口在当前时间片的占比
- 计算当前窗口在上一个时间片的剩余占比,并假设上一个时间片内的请求是均匀分布的
- 由公式:
当前总请求次数 = 当前时间片计数 + 上个时间片计数 * 上一个时间片的剩余占比,如果这个总请求次数不超过可用配额,则允许当前请求,否则拒绝当前请求。
下图演示了一个
优点:
- 该算法平滑了流量的峰值,因为请求速率是基于前一个时间片的平均速率
- 高效存储
缺点:
- 该算法只适用于不那么严格的回顾窗口,因为它假设上个时间片的请求是均匀分布的。但是这个问题并没有那么严重,因为该算法被Cloudfare使用,在他们的统计报告中,4亿个请求只有0.003%被错误允许。
Step3:Design deep dive
详细设计(Detail Design)
在展示详细设计前,先做一些铺垫:
计数器存储(Stored Counter)
上述限流算法在实际应用中最广泛的是令牌桶,其次是滑动窗口计数器,实现这两个算法都需要计数器来统计有多少个请求发送自相同的user或IP。那么我们应该将计数器存放在哪里呢?
存放在数据库中不是一个好主意,因为磁盘访问太慢了,每有一个请求就访问一次数据库,对数据库造成的压力也会非常大。内存缓存(In-memory cache)是一个不错的选择,因为它访问速度快,并且支持基于时间的过期策略(LRU等)。现实世界中,Redis就是一个非常受欢迎的选择,对于内存存储它提供了两条命令:INCR和EXPIRE.
- INCR:该命令将存储计数器+1
- EXPIRE:该命令为存储计数器设置一个过期时间。过期后将对应的存储计数器删除。
限流规则(Rate Limiting Rules)
下面是一些限流规则举例,这些规则通常被存放在XML或YAML中,以方便修改:
# 该系统被配置为:每天最多允许5条营销信息
domain: messiaging
descriptors:
- key: message_type
value: marketing
rate_limit:
unit: day
request_pre_unit: 5
# 该系统被配置为:每分钟最多登录5次
domain: auth
descriptors:
- key: auth_type
value: login
rate_limit:
unit: mintue
request_pre_unit: 5请求受限(Exceeding the rate limit)
在请求受限的情况下,我们对于无法立即处理的请求,通常有两种选择:
option1:直接将请求丢弃
option2:将请求排入消息队列,以便稍后处理
上面2种选择是在服务器端的响应,在客户端都是返回HTTP429:too many request。
在2023年3月份使用ChatGPT时,非常容易碰到HTTP429的情况。
基于以上几点,下图演示了一个限流器中间件的详细设计:
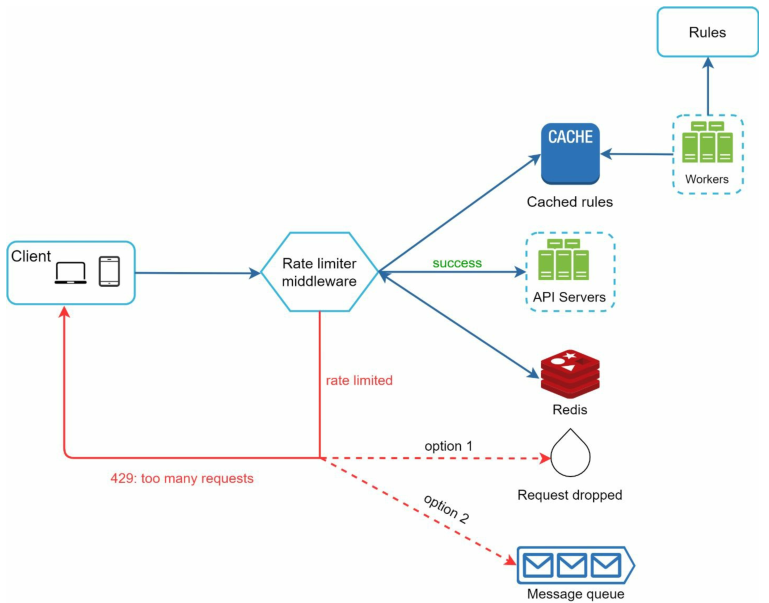
- 规则文件(XML、YAML)存储在磁盘上,workers服务器会定期从磁盘中提取规则并将其存储在缓存中
- 客户端向服务器发送请求时,该请求首先会被发送到限流器中间件
- 限流器中间件从缓存中加载规则。并从Redis缓存中获取计数器和最后一个请求的时间戳。然后根据限流器中的限流算法,限流器将做出以下决定:
- 该请求不被限制,它会被发送到API服务器
- 该请求受到限制,它向客户端返回HTTP429,与此同时,请求要么被丢弃,要么转发到消息队列
分布式限流器(Rate Limiter in distributed environment)
分布式限流器主要会遇到两个问题:竞态条件和同步问题
这两个问题和操作系统并发(多线程)的问题很像。
竞态条件(Race Condtion)
redis是单线程的,然后在分布式架构里是怎么处理竞态条件的?
redis的sorted set
https://engineering.classdojo.com/blog/2015/02/06/rolling-rate-limiter/
简单来说,就是利用了redis sorted set,其所有 redis 操作都可以作为原子操作执行。
redis + lua脚本
https://gist.github.com/ptarjan/e38f45f2dfe601419ca3af937fff574d#request-rate-limiter
简单来说,redis会将整个lua脚本作为一个原子命令执行,因此无需担心并发操作
同步问题(Synchronization)
当同一个客户端向不同的限流器发送请求时,它的计数器等参数必须要共享才行:
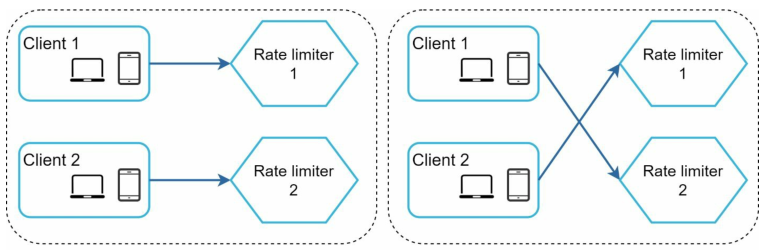
实际上,这也能够通过redis解决,因为这些参数都是存放在redis里的,保证redis的一致性就行:
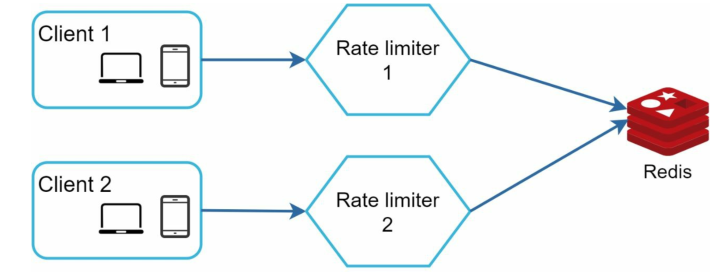
Step4:Warm up
如果时间允许,你可以与面试官讨论包括但不限于以下要点:
硬速率限制vs软速率限制
- 硬速率限制:请求数量在任何时段都不能超出阈值
- 软速率限制:请求数量可以在短时间内超出阈值
在不同层级使用速率限制
- 在本章中,我们只讨论了应用程序级别(HTTP: layer7)的速率限制。你也可以尝试在其它层使用速率限制,例如,在网络层(HTTP:layer3)使用IPtable对IP地址进行速率限制等等。
如何避免客户端受到速率限制
- 使用客户端缓存,避免频繁调用API
- 为重试逻辑增加足够的缓冲时间(验证码60s才能发送一次)
- 返回醒目信息,让user明确了解当前的速率限制
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!