系统设计-Ch6-设计一个Key-Value存储引擎
设计一个Key-Value存储引擎
首先讲两个术语,数据库和存储引擎。数据库往往是一个比较丰富完整的系统, 提供了SQL查询语言,事务和水平扩展等支持。而存储引擎则是小而精, 纯粹专注于单机的读/写。一般来说, 数据库底层往往会使用某种存储引擎。因此二者其实是包含关系,实现一个数据库之前首先要实现一个存储引擎。
在本章中,你被要求设计一个Key-Value存储引擎,其支持以下基本操作:
put(key, value),插入一个键值对get(key),读取一个键所关联的值
没有完美的设计,每种设计一方面要在读、写、内存使用中做出权衡,另一方面要在一致性和可用性之间做出权衡。在本章中,我们设计一个常见的key-value存储引擎,该存储引擎包含以下特征:
键值对的大小很小,小于10KB
具备存储大数据的能力
高可用性:即使在出现故障时,系统也能很快响应
高可扩展性:系统可以扩展以支持多台服务器分布式运作
自动扩展:服务器的添加/删除应根据流量自动调整
可调一致性(最终一致性)
最终一致性:表示如果有足够的时间,所有更新都会传播,从而最终保证所有副本都是一致的
低延迟
我们从易到难,先讲单服务器存储,在讲分布式存储
单服务器key-value存储引擎
开发一个只运行在一个服务器上的key-value存储引擎很容易。一种很容易想到的方式是直接将键值对存储在哈希表中,即使用unordered_map(c++)这种数据结构,将所有数据都保存在内存当中。
因为访问内存很快,这种方式读写效率高。但是内存空间是有限制的,很可能无法将所有内容都放进内存。为了在单服务器中容纳更多数据,可以进行两种优化:
- 数据压缩
- 采用LRU策略,仅将常用数据存储在内存中,其余数据存储在磁盘上
即使进行了这些优化,单个服务器的内容也容易很快达到其存储容量上限,因此需要分布式存储以支持大数据
分布式key-value存储引擎
分布式key-value存储引擎也称为分布式哈希表,它将键值对分布在许多服务器上。
在设计分布式系统时,理解CAP定理(Consistency, Availability, Partition Tolerance)是十分重要的。
CAP定理
在了解CAP定理之前,要先清楚Consistency, Availability, Partition Tolerance这三个属性:
- Consistency(一致性):一致性意味着所有Client无论连接到哪个Server节点,都能同时看到相同的数据。
- Availability(可用性):可用性意味着任何请求数据的Client都会得到响应,即使某些Server节点宕机。
- Partition Tolerance(分区容差):分区容差意味着尽管Server节点之间存在网络分区(分区之间无法相互通信),系统仍然能继续运作。
CAP定理指出:必须牺牲三个属性中的其中一个来支撑另外两个属性,如下图所示:
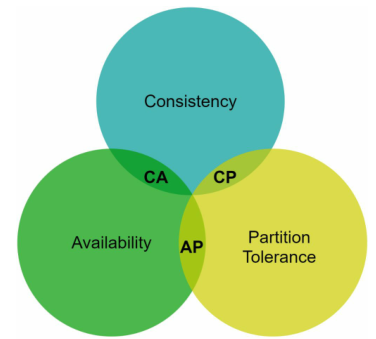
现实世界中,由于网络故障是不可避免的,因此必须容忍网络分区,即保证Partition Tolerance。
因此一个分布式系统要么侧重一致性,要么侧重可用性,必须在这二者之间做出取舍。
如果我们选择一致性而不是可用性,当其中一个Server无法与其它Server通信(发生网络分区)时,我们必须阻止对其它Server的写入操作,以避免Server之间的数据不一致性。像银行系统通常就要求极高的一致性。
如果我们选择可用性而不是一致性,当其中一个Server无法与其它Server通信(发生网络分区)时,其它Server会继续接受写入,缺点就是这个Server被读取后会返回过时的数据,直到网络通信恢复使得Server之间数据同步。
系统组件
数据分区(Data Partition)
对于大型应用程序,将完整的数据集放在单个服务器中是不可行的。更好的方式是将数据拆成更小的分区,然后将它们存储在多个服务器中,这就是数据分区。对于数据分区有两个挑战:
- 将数据均匀分布在多个服务器上
- 在添加或删除节点时最大限度地减少数据移动
第五章介绍的一致性哈希是解决数据分区这个问题的一种很好的技术。
数据复制(Data Relication)
为了实现高可用性(availability),必须在N(N是一个可配置参数)台服务器上异步复制数据。
这N台服务器是使用如下逻辑选择的:
在密钥(key)映射到哈希环上的某个位置后,从该位置顺时针走,然后选择环上的前N个服务器来存储数据副本。
N个服务器是指N个真实节点服务器,如果顺时针上有多个虚拟节点指向同一个真实节点,只选择其中第一个
如下图所示,当N=3时,key0在s1, s2, s3处被复制:

一致性(Consistency)
由于数据是在多个节点上复制的,因此必须跨复制副本进行同步。这里引入仲裁机制
- N = 副本数
- W = 写入仲裁数。要使得写入操作成功执行,必须等待直到至少W个副本确认写入操作
- R = 读取仲裁数。要使得读取操作成功执行,必须等待直到至少R个副本响应读取操作
N、W、R的配置是延迟和一致性之间的典型折衷:
- 如果W = 1 或 R = 1,意味着系统会快速响应读写操作或读操作,因为仲裁者只需要等待来自任一副本的响应
- 如果W+R>N,意味着系统具有强一致性,因为W+R>N保证了系统有一个具有最新数据的节点(读写重叠)
不一致解决方案(Inconsistency Resolution)
首先来看看不一致性是怎么发生的,如下图所示:
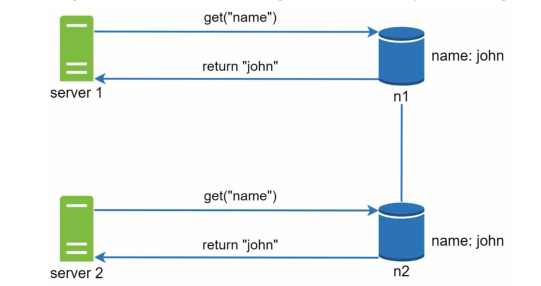
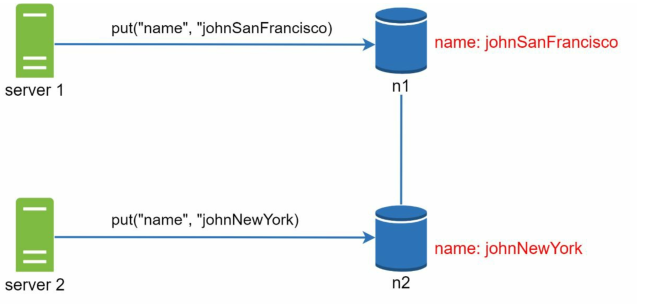
简而言之,就是多台Server取出同一数据,并同时更改为不同的值然后回写,此时就发生了冲突。
为了解决这个问题,我们需要一个能检测冲突并协调冲突的版本控制系统—vector clock。
Vector Clock
vector clock,是一个与数据项相关联的[server, version]键值对。
假设一个vector clock由,其中是数据项,是服务器编号,是版本计数器。那么如果有数据项被写入服务器,则系统必须执行以下任务之一:
- 如果存在,增加的计数
- 否则,创建一个新的条目
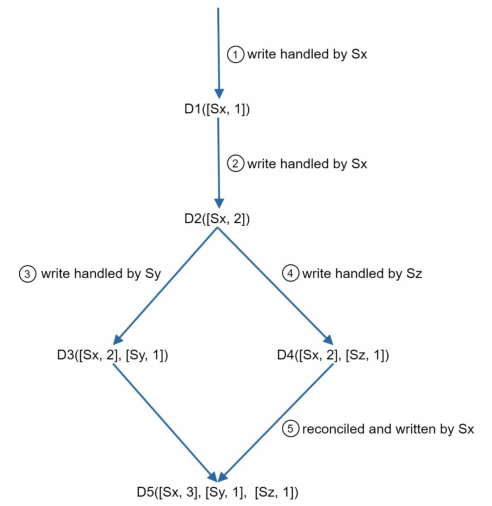
通过使用vector colck,我们可以很快的检测冲突:
- 例如和,前者的每个server的版本都大于等于后者对应server的版本,因此可以判断出后者是前者的祖先
- 例如和,出现版本相互超越对方,可以判断出二者是兄弟(存在冲突)
检测出冲突后,可以设计实现一个冲突解决逻辑。
亚马逊Dynamo就是采用vector clock实现版本控制的。
故障处理(Handing failures)
在本小节中,我们首先讨论故障检测的技术,然后我们讨论常见的故障解决策略。
故障检测
在分布式系统中,不会因为另一台服务器说某台服务器坏了就相信它是坏的,通常需要两个独立的信号源来标记一台服务器。
全对全广播(all-to-all ,multicasting)是一种简单的解决方案,如下图所示:
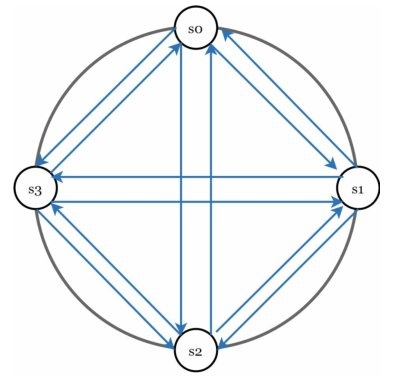
但是,当系统中有许多服务器时,这会变得非常低效。
更好的方案是使用离散的故障检测方法,如八卦协议(gossip protocol)。八卦协议的工作原理如下:
- 每个节点都维护一个节点成员列表,其中包含成员ID和心跳计数器
- 每个节点周期性地递增自身的心跳计数器
- 每个节点周期性地向一组随机节点发送心跳
- 一旦节点成功接受到心跳检测信号,其节点成员列表就都会更新为最新信息
- 如果心跳没有增加超过预定义的时间段,则该节点视为离线
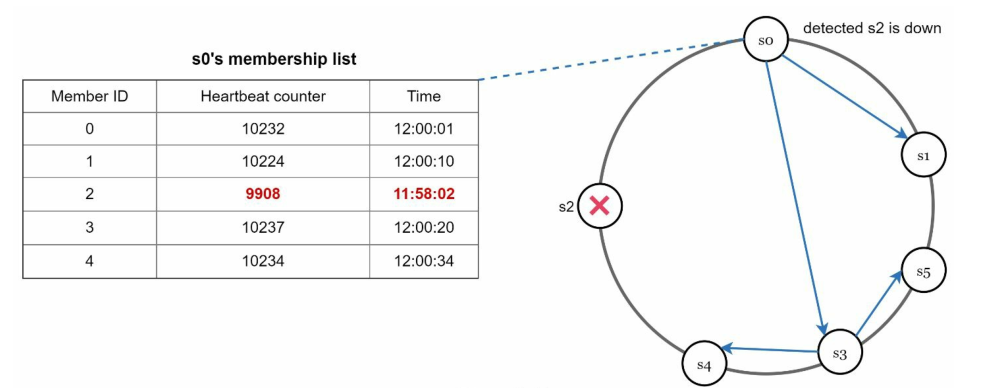
如上图所示,s0的成员列表中有s2,s0注意到s2的心跳计数器长时间未增加,然后s0就把这个消息发送到一组随机节点,一旦其它成员列表也有s2的节点确认了s2的心跳计数器长时间未增加这个消息,则s2被标记为宕机。
故障
系统架构图
现在我们将重心转移到key-value存储引擎的架构图上:
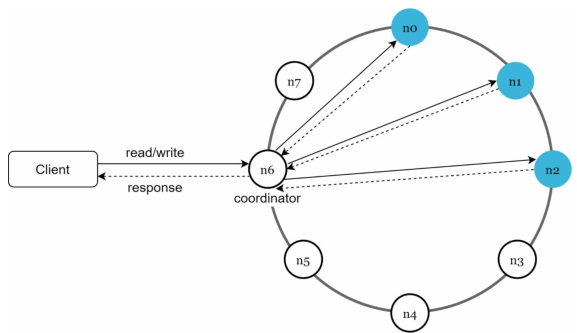
如上图所示,该系统架构的特点如下:
- 客户端(client)通过
get (key)和put(key, value)这两个API来与key-value存储引擎交互 - coordinator是一个在client和key-value存储引擎之间充当代理的节点
- 节点使用一致性哈希分布在一个哈希环上
- 数据在多个节点上进行复制
- 不存在单点故障,因为每个节点都有相同的责任,并且每个节点都可以执行多个任务
写入路径
缓存满了或达到预设阈值时写入磁盘
读取路径
类似redis,缓存命中则不从磁盘读取
总结
本章涵盖了许多概念和技术,下表汇总了用于分布式key-value存储引擎的功能和相应技术:
| 目标/问题 | 技术 |
|---|---|
| 使系统具备存储大数据的能力 | 使用一致性哈希 |
| 高可用读取 | 数据复制 |
| 高可用写入 | 使用vector clock检测冲突和解决冲突 |
| 数据复制 | 一致性哈希 |
| 自动扩展 | 一致性哈希 |
| Heterogeneity | 一致性哈希 |
| 可调一致性 | 仲裁机制 |
| 处理临时性故障 | 草率仲裁&提示切换 |
| 处理永久性故障 | Merkle tree |
| 处理数据中心停电 | 交叉数据中心复制 |
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!