系统设计-Ch13-设计一个搜索自动补全系统
设计一个搜索自动补全系统
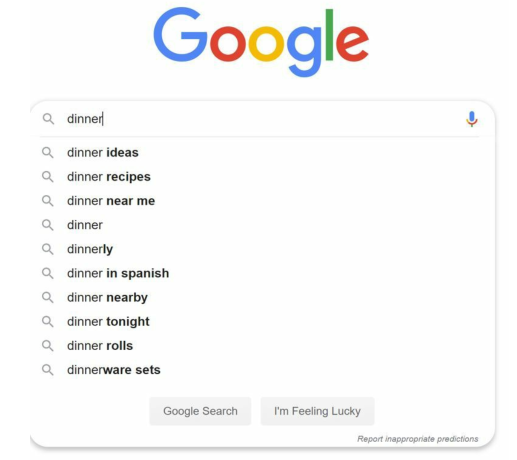
当你使用Google搜索时,每当你在搜索框键入一个字符,下方都会出现与搜索词匹配的内容,这个功能叫搜索自动补全(Search AutoComplete)。如下图所示,当你在搜索框中键入了一个dinner时,显示了自动完成的结果列表:
对于在搜索输入框中的每个字符,客户端都会向后端发送请求以获取自动补全建议
比如当你键入dinner时,
search?q=d
search?q=di
search?q=din
search?q=dinn
search?q=dinne
search?q=dinnerSearch AutoComplete 是许多产品的一个重要功能,这就引出了面试的问题–设计一个搜索自动补全系统。
Step1:Understand the problem and establish design scope
对于”设计一个搜索自动补全系统“这个系统设计话题,我们可以向面试官提出以下问题:
Q:匹配是只支持头部匹配么?,还是中间也要匹配?
A:仅支持开头匹配
Q:系统应该返回多少个自动补全建议?
A: 5个
Q:系统怎么知道该返回哪5个建议?
A:这是由搜索热度决定的,专业点来说就是历史查询频率
Q:我们是否允许大写、中文和特殊字符?
A:我们假设所有查询都只包含小写字母
Q: 该产品的日活量是多少?
A:1000W日活跃用户(DAU, Daily Active Users)
Step2:Propose high-level design and get buy-in
在高级设计中,该系统分为两部分:
- Data gathering Service(数据收集服务):它收集用户输入的查询,并实时聚合这些查询。实时处理对于大型数据集并不适用,但这是一个很好的起点,我们将在deep dive中探讨更现实的解决方案
- Query Service(查询服务):给定搜索查询或前缀,返回5个最常见的搜索词
Data Gathering Service
让我们用一个简单的示例来了解数据收集服务的工作原理:
假设我们有一个频率表,它用于存储查询字符串及其频率,如下图所示:
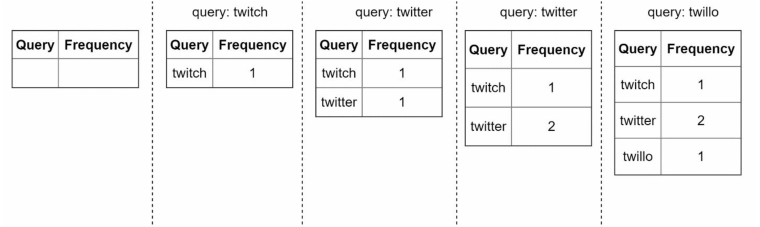
一开始,频率表是空的。随后,用户依次输入查询twitch、twitter、twitter、和twillo。就是这样简单的记录查询次数。
Query Service
对于上面的那个频率表,我们有两个字段:
- Query:存储被查询的字符串
- Frequency:存储字符串被查询的次数
那么当用户在搜索框中输入tw时,将显示以下前5个搜索查询,如下图所示
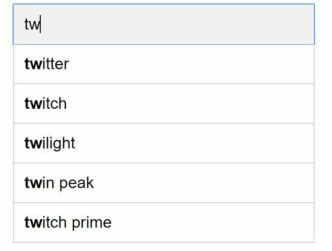
执行以下SQL可以获取前5个经常搜索的查询:
SELECT * FROM frequency_table WHERE query Like `prefix%` ORDER BY frequency DESC LIMIT 5当数据库很小时,这是一个可接受的解决方案。当数据库很大时,数据库访问就会成为瓶颈。我们将在deep dive中探讨优化。
Step3:Design deep dive
在High-Level Design中,我们讨论了数据收集服务和查询服务。虽然High Level Design中的设计并不是最优的,但却是一个很好的起点。在本节中,我们将深入研究以下几个组件:
- Trie数据结构
- 数据收集服务(再设计)
- 查询服务(再设计)
- 扩展存储
- 试运行
Trie Data Structure
从关系性数据库中获取前5个搜索频率最高的字符串是低效的,数据结构Trie可以克服这个问题。
本文中我们主要讨论Trie数据结构是如何做到优化的:
首先我们要了解Trie的基本性质,想要了解其具体实现,可以参考这篇文章
- Trie是一种树状数据结构
- 根节点(root)表示空字符串
- 每个节点存储一个字符,会有额外的数组标记当前是否是一个完整的前缀
下图显示了一个Trie,其中包含搜索查询tree、try、true、toy、wish、win。
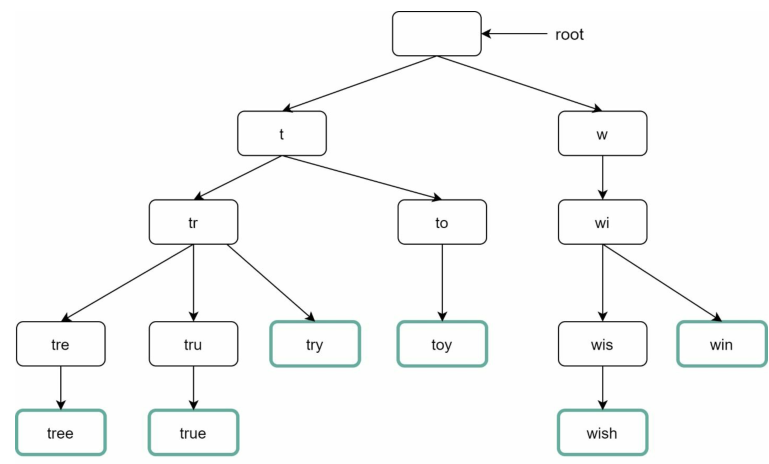
为了支持按频率排序,需要在节点中包含频率信息,向节点添加频率信息后,更新的Tire数据结构如下图所示:
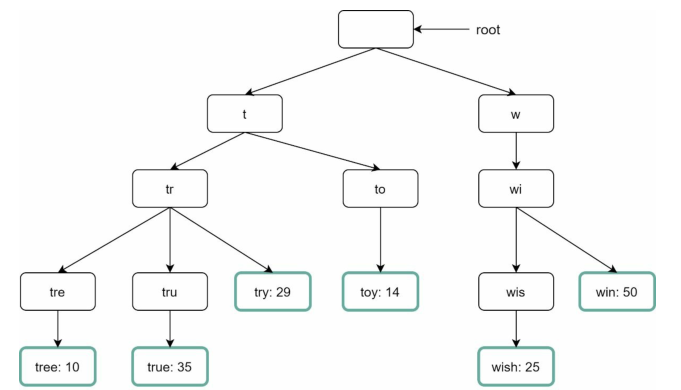
autocomplete如何与Trie一起工作?让我先定义一些术语:
- :查询字符串的长度
- :trie中节点总数
- :节点的子节点个数
下面给出了获取搜索次数最多的前k个查询的步骤:
- 在Trie中找到前缀,时间复杂度
- 遍历前缀节点的子树,得到所有有效的子节点。如果子节点的字符与查询字符串的字符匹配,则是有效节点,时间复杂度
- 对子节点进行排序,并得到top k个,时间复杂度
下面让我们用图示来解释上述算法:
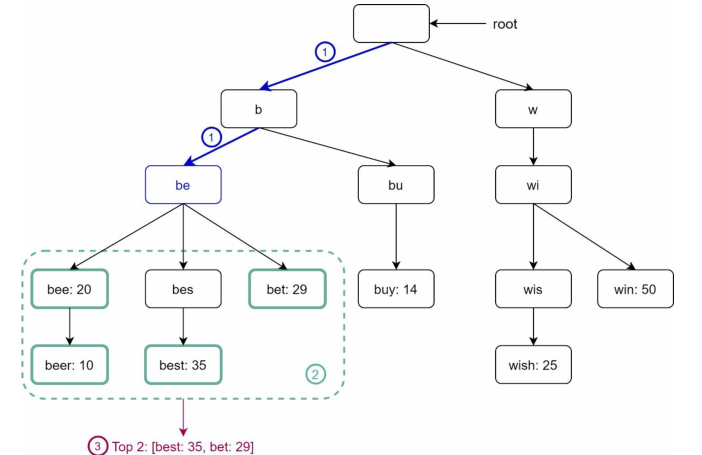
假设的取2,用户在搜索框中键入tr,那么过程如下:
查找前缀
tr遍历所有子节点得到所有有效的子节点,在这种情况下:
子节点
[tree: 10]、true: 35、try: 29是有效的对有效的子节点进行排序,前2名是
true和try
该算法的时间复杂度是上面提到的每一步的总和,即
然而这个算法太慢了,我们需要遍历整个Trie来获取前k个结果。以下是两个优化:
- 限制前缀的最大长度
- 在每个节点设置缓存,在缓存中找到热门查询后直接返回(不继续向下搜索子节点)
Limit the max length of a prefix
一般来说,用户很少在搜索时键入较多的字符串。因此,可以很肯定的说是一个小整数,比如50。如果我们限制的最大长度,那么查找前缀的时间复杂度就把限制在常数范围内。
Cache top search queries at each node
为了避免遍历整个Trie,我们在每个节点存储前k个最常用的查询。由5到10个自动补全建议对用户来说已经足够了,所以是一个相对较小的数字,这里我们假定是5。
通过在每个节点缓存排名靠前的5个查询(这样每个节点都要花费大量额外空间),我们可以显著降低时间复杂度,相当于空间换时间,但这是十分值得的,因为需要快速响应因此时间很重要。
下图显示了更新后的Trie数据结构。前5个查询存储在每个节点上。例如前缀为be的节点存储以下查询:
[best: 35],[bet: 29],[bee: 20],[be: 15], [beer: 10]
在应用了这两个优化后,让我们重新来看看算法的时间复杂度:
- 查找前缀节点:时间复杂度
- 返回Top k个查询,由于Top k的查询被缓存,所以理论上时间复杂度是均摊
Data Gathering Service
在我们之前的设计中,每当用户键入搜索查询时,数据都会实时聚合。由于以下两个原因,这种方式不实用:
- 用户每天可能输入数十亿个查询,在每个查询后更新trie会显著降低查询服务的速度
- 一旦建立了Trie,顶级建议可能不会有太大变化,因此没有必要频繁更新Trie
为了设计一个可扩展的数据收集服务,我们首先要确定数据来源,以及如何使用数据。
像Twitter这样的实时应用程序需要最新的auto-complete建议,然而,许多谷歌关键词的auto-complete可能每天都不会有太大变化。
尽管用例存在差异,但是数据收集服务的基础仍然是相同的,因为用于构建Trie的数据通常来自分析或日志记录服务。
下图显示的重新设计的数据收集服务,让我们来一一说明每个组成部件:

Analytics Logs。它存储着有关搜索查询的原始数据。日志仅附加,不编制索引,,下表显示了日志文件的一个示例:
Aggregator。分析日志的大小通常分长达,并且数据格式不统一,我们需要汇总数据,以便后续处理
根据使用情况,我们可能会以不同的方式聚合数据。对于像Twitter这样的实时应用程序,我们在更短的时间间隔内聚合数据,因为实时结果很重要。另一方面,聚合数据的频率较低,比如每周一次,对于许多情况下已经足够了。在面试过程中,验证实时结果是否重要。我们假设Tire每周都会重建。Aggregator Data。下表显示了汇总每周数据示例。
Worker。worker是一组服务器,它们定期执行异步作业。他们负责构建trie并将其存储在TrieDB中。
Trie Cache。Trie Cache是一个分布式缓存系统,它将Trie保存在内存中以实现快速读取
Trie DB。Trie DB是持久存储,有两个选项可用于存储数据:
- trie中的每个前缀都映射到哈希表中的一个key
- 每个Tire节点上的数据都映射到哈希表上的一个value
下图显示了trie和哈希表之间的映射,左边的trie节点都映射到右边的<key,value>中:

Query Service
在High Level Design中,查询服务直接调用数据库以获取前5个结果(效率低下),下图显示了改进后的设计:

- 将搜索查询发送到负载均衡器
- API Server从Trie Cache获取Trie数据,并为客户端构建auto-complete建议
- 如果数据不在Trie Cache中,会将数据补充回缓存
查询服务需要闪电般的速度,我们建议采取以下优化:
- AJAX请求。对于web应用程序,浏览器通常发送ajax异步请求来获取auto-complete建议
- 浏览器缓存。对于许多应用程序,auto-complete建议短时间可能不会变化很大,因此可以保存在浏览器缓存中,正如下图所示,谷歌将结果缓存在浏览器中,图中的
maxage = 3600表示缓存3600秒,也就是1小时:

Scale The Storage没有什么价值,不写了
Step4:Warm up
如果你还剩下一些时间,可以与面试官讨论以下问题:
如何扩展你的设计以支持多种语言?
为了支持其它非英语查询,我们可以考虑将Unicode字符存储在Trie节点中,Unicode字符涵盖了世界上所有语种的字符
如果一个国家的热门搜索与其它国家的不一样怎么办?
不同国家建立不同的Trie,CDN分发
如何支持实时搜索查询?假设一个新闻事件爆发,那么短时间相关词条的查询就会流行起来
构建实时搜索查询是复杂的,超过了本书的范围,因此只给出几个想法:
- 通过分片减少数据集
- 更改排名模型,为最近的查询分配更多的权重
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!