Oriented RepPoints
Oriented RepPoints
Introduction
论文题目 :Oriented RepPoints for Aerial Object Detection
论文地址 :https://arxiv.org/pdf/2105.11111.pdf
论文出处 :2022’CVPR
代码实现 :https://github.com/LiWentomng/OrientedRepPoints
Idea
1.提出3种定向转换函数,将每个特征图中的点集(9个点),转换成有向的框。
2.点集学习提出了一种有效的 自适应点评估和分配样本方案APPA 。
3.为了匹配定向目标数据和转换函数,提出了损失函数的改进。
Detail
Related Work
此前,基于角度回归的检测方法在该研究领域占主导地位(通过直接添加角度参数),
但是直接方向预测会带来一系列问题=>包括 损失的不连续性 和 回归的不一致性
这两个问题主要是由于角度的周期性(有界)和旋转框的定义表示。
这就导致虽然定位比较准确,但是旋转方向的回归很多时候是不太准确的。
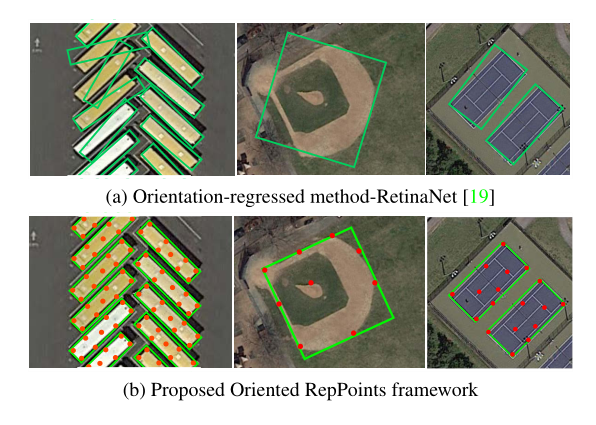
在传统通用检测器中,RepPoints通过使用点集表示来捕获细粒度对象。
Oriented RepPoints
[Pre]-可变形卷积(DCN)
ICCV2017: Deformable Convolutional Networks
这是可变形卷积想要表达的采样形式,a是代表普通的卷积核是3*3的,所示采样的点数是9个,b,c,d都是可变形卷积(c、d只是一种特殊的形式),可以看出a普通卷积采样的位置是固定的,而可变形卷积做的事情就是给9个采样点,每一个点加一个偏移量得到新的采样坐标(偏移量是小数,例如原一个采样点坐标(3,4)加上偏移量可能为(3.6,5.8)坐标变成了小数,这个时候就用双线性插值法为该点取值),把新的9个位置作为可变形卷积采样点的位置,然后再进行常规的卷积加权的操作。只是改变了采样点的位置。
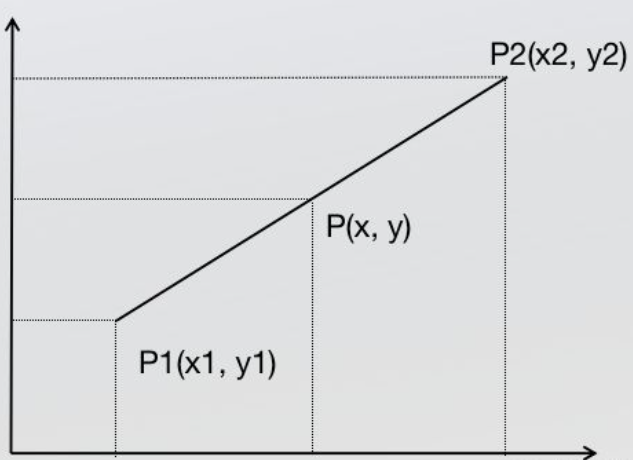
- 单线性插值
根据同一条直线斜率相等,可得:
整理得:
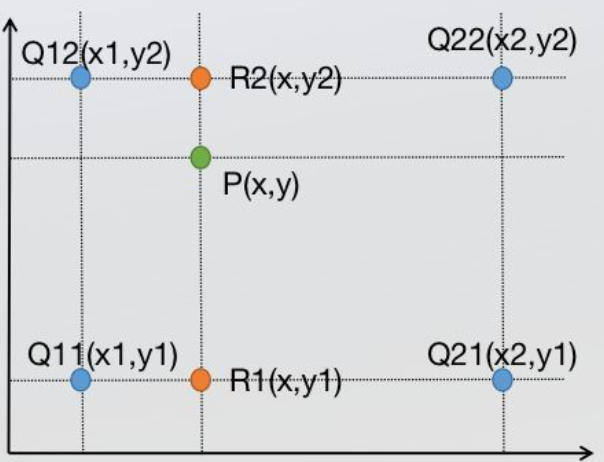
- 双线性插值
就是选择周围相邻的四个点进行三次单行线插值,其中x轴2次,y轴1次。
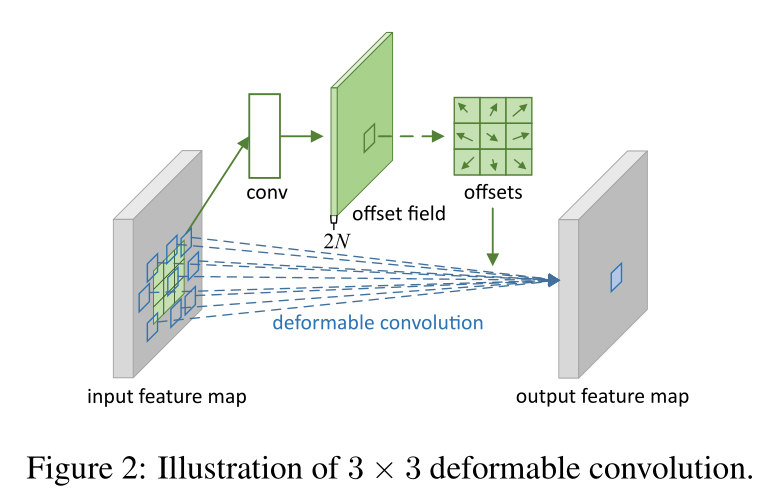
再说一下可变形卷积的结构,先从输入的特征图中,单独用一个小的卷积分支对特征图中的每一个点都学习一组偏移量的信息offset field(这里的通道数是2N,N表示采样点的个数3*3的卷积核N在这里表示9,2表示每个采样点都有x坐标偏移值和y坐标的偏移值),用来表示当卷积核的走到特征图该点的时候应该偏移到哪个位置来计算。这个偏移量没有具体的取值范围,offsets学出来值的应该是有正有负的小数(正负代表方向),代码中也有后处理来保证加上偏移量的新采样的位置不会超过特征图的范围 。这个offsets就是点集表示目标的关键。
[Pre]-RepPoints
ICCV2019: RepPoints: Point Set Representation for Object Detection
RepPoints点集表示的目标检测属于anchor free的表示。
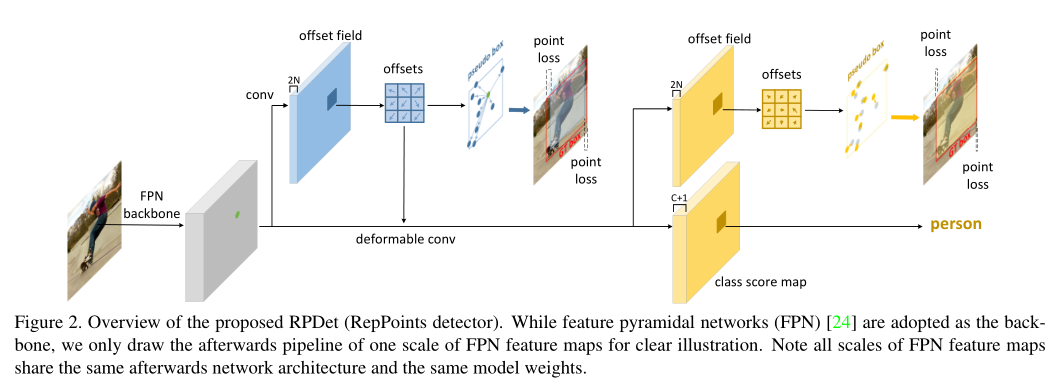
整体上来看这个网络分为定位和分类两个内容。这个网络的训练定位是分为两个阶段,分类是一个阶段。
下面具体来看下网络结构:
首先这个网络的backone是用的FPN,出来的是5个层级的Scale的特征图,在此处只对一个特征图出来的head举例子。一层特征图出来被分为两个分支,一个用来做目标的定位,另一个用来做分类。
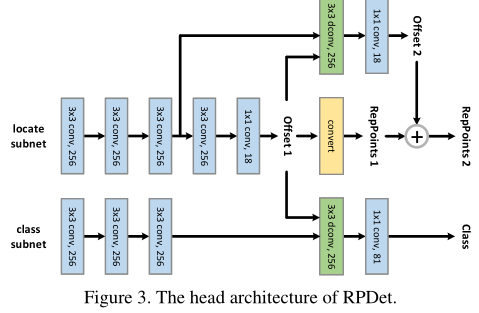
定位: 定位部分有两个阶段:
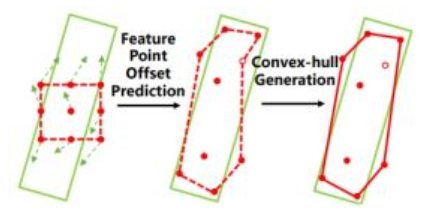
第一阶段:先做一次3x3的卷积学习一下特征,然后1x1的卷积用来改变通道产生offsets,再进入offset field进行可变形卷积得到每个点的x方向和y方向上的偏移量,我们得到了一组点集9个点的坐标,在通过转换函数Convert即可以生成pseudo box(伪框)。
转换函数Convert有三种:
1.Min-max function. 通过点集所有点的x,y坐标的最大最小值画框。
2.Partial min-max function. 通过点集部分点(文章中指出代码中是前四个点)的x,y坐标的最大最小值画框。
3.Moment-based function. 通过一组点集中点位置的均值和标准差回归出框的位置。
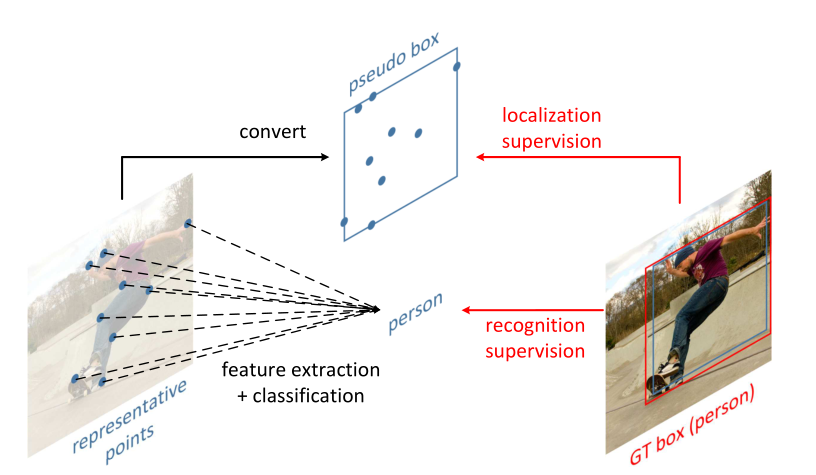
Positive:
1.根据GT的尺寸大小,选择某一个scale的特征图,将GT映射在该特征图上(中心点映射)
2.第一阶段产生的所有pseudo box中与GT的IOU的值大于0.5,评判为positive,进入第二阶段
第二阶段: Refine stage,与第一阶段步骤大致相同,可以看到point loss明显变小。
分类: 分类分支也是对positive pseudo box(有目标的框)做分类,第一阶段产生的pseudo box与GT的IOU大于0.5认为有目标的框做分类损失,用的是focal loss。
Network
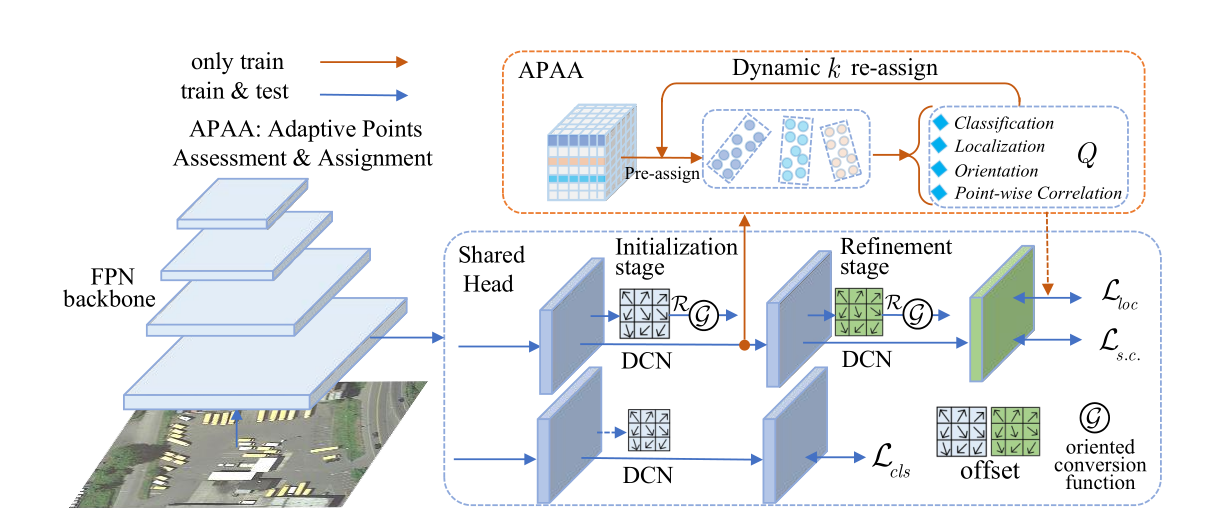
Oriented conversion function
三个定向转换函数
1.MinAeraRect :在采样点中选择具有最小面积的旋转矩形;(该函数不可导在网路中训练参数不可以反传,所以只在推理的时候应用)
2.NearestGTCorner :GT的四个角点,找4个距离最近采样点作为预测点。
3.ConvexHull:通过Jarvis March算法,找到包围所有采样点的外接多边形。
Adaptive Points Assessment and Assignment
自适应点集评估和分配样本方案
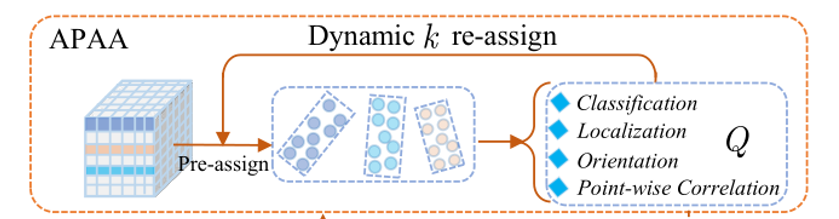
该方案是在pseudo box与GT box的IOU>0.5的基础上,对这些pseudo box再从四个方面来衡量质量的好坏,然后按照质量分数对其进行排序,通过一个采样率选择质量分数Top前几的作为positive样本进行细化,通过此方式训练的网络可以更好。
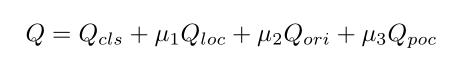
1.分类质量:该点集与GT的分类损失focal loss
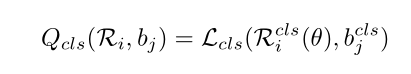
2.定位质量:该点集生成的多边形与GT的GIOU损失值
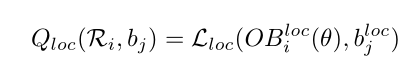
3.定向质量:通过倒角距离(Chamfer distance)来衡量
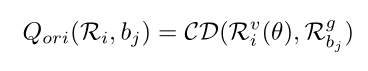
4.逐点相关性质量
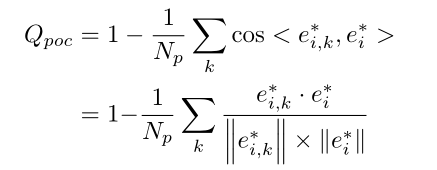
动态Top K分配:选择根据前面4个质量标准,质量分数排在前面k的点集生成的pseudo box去做第二阶段的细化。
Loss function
NearestGTCorner 和 ConvexHull 转换函数实际上生成的不是一个规则的矩形,而是一个不规则的四边形和多边形。所以这个时候就能用GT的角点来衡量loc的损失,这里是用的GIOU的损失,也对分布在GT范围以外的离群点做了惩罚。惩罚项就是对超出GT的离群点做惩罚,让所有的点分布在GT box之内。(通过惩罚监督,边形框就会越来越接近标准的矩形)
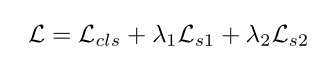
分类:
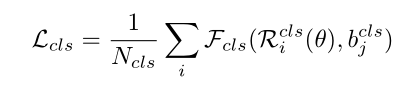

有向定位框:
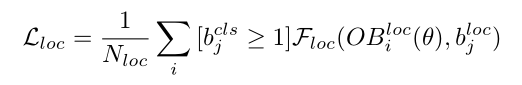
离散点惩罚:

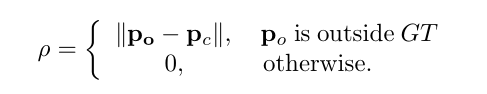
实验部分
Oriented R-CNN
有两个问题:
map比论文中的大
应该是要取多个阈值训练下的平均值。
voc07通过将IoU从0.5变化到0.95计算不同的mAP,再求平均,更能反映出定位精度
与github上给出的log.json还有一定差距(4%),不知道是不是参数的设置,准备做一个json比对。
我自己跑过两个相同的训练,相差只有0.2%左右。
mutilscale数据集
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!