Vision Transformer
Vision Transformer
Vision Transformer
论文题目 :AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
论文地址 :https://arxiv.org/pdf/2010.11929.pdf
论文出处 :ICLR’2021
代码实现 :-
Idea
通过将图像拆分为块 (patch),并将这些图像块的线性嵌入序列作为 Transformer 的输入,作者将Transformer成功应用到CV领域。
没有直接把像素点作为输入,可以减少参数量
通过这篇文章的实验,说明Transformer在CV领域确实有效,并且效果惊人。
Detail
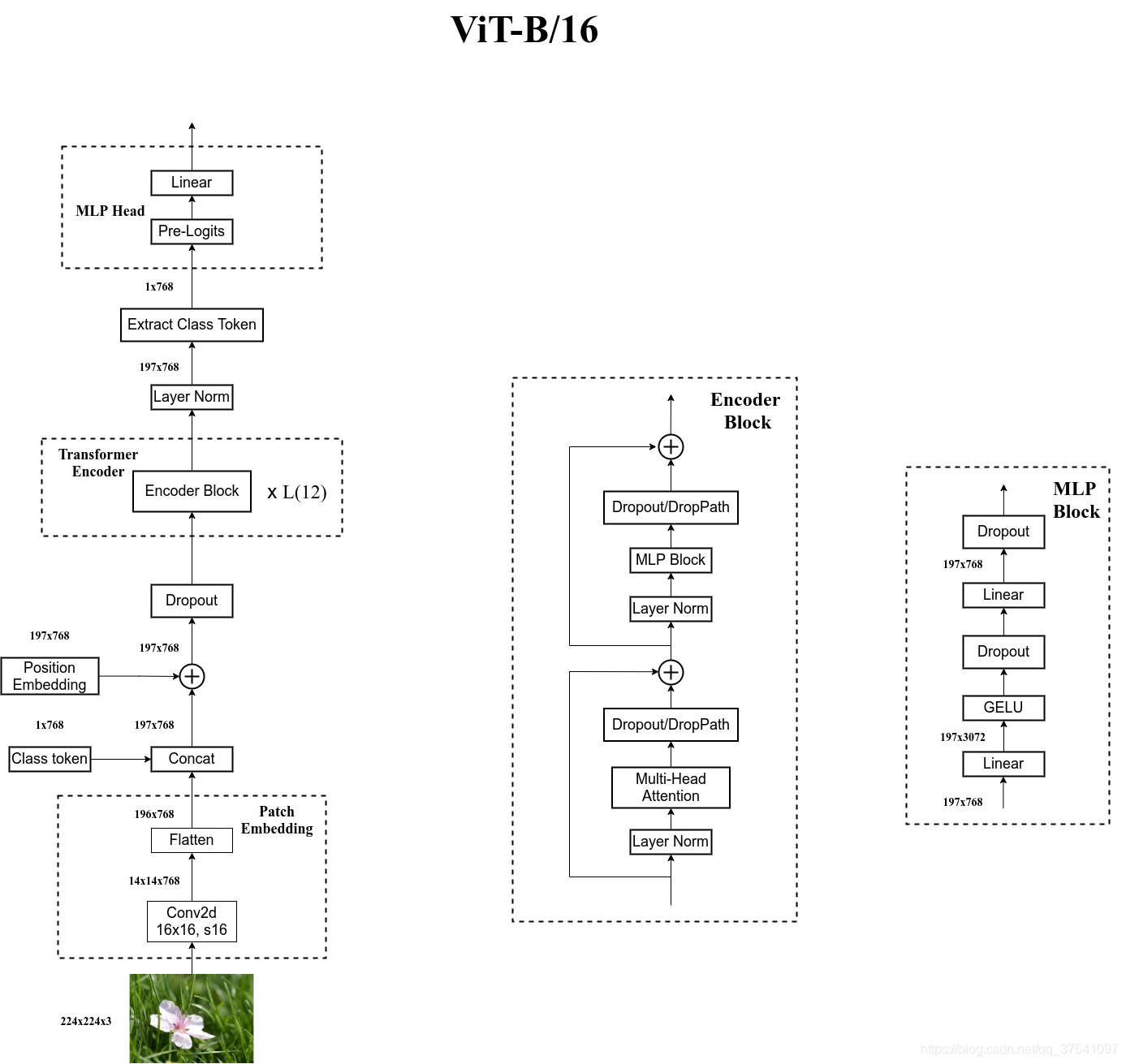
Network
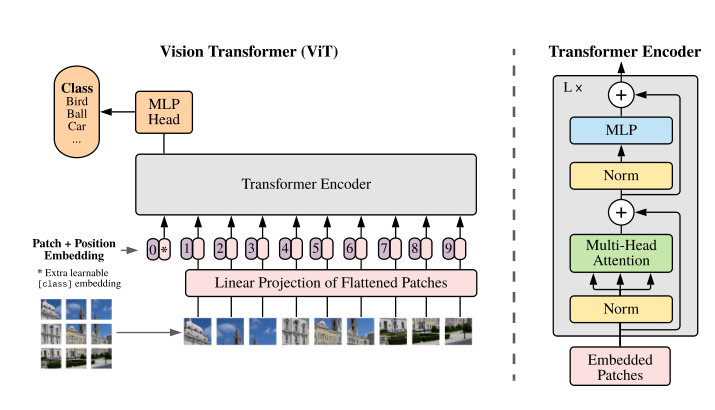
- Linear Projection of Flattened Patches(Patch Embedding层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)
Patch Embedding
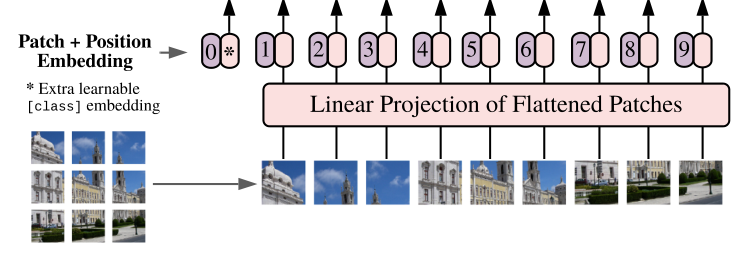
以ViT-Base/16为例:
首先将一张图片按给定大小分成一堆Patches。将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到(224/16)^2 = 196 个patch。
每个Patche数据shape为[16,16,3]通过线性映射将每个Patch映射到一维向量中,映射得到一个长度为768的向量token[196,768]。
具体使用一个卷积层(768个16x16的卷积核,stride为16)来实现Patch划分。
拼接一个[class]token, Concat([1,768],[196,768] => [197,768]。
叠加位置编码Position Embedding, [197,768] => [197,768]。
自注意力的扰动不变性(Permutation-invariant): 打乱 Sequence 中 tokens 的顺序并不会改变结果。
这里的[class] token和位置编码都是可训练参数。
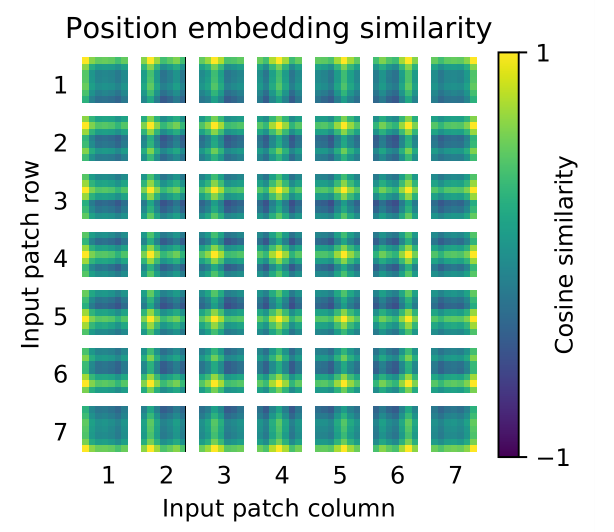
位置编码之间的余弦相似度可视化,表明任意两个patches之间在位置上的关联度。
可以发现相近的图像块的位置编码关联度较高,且同行或列的位置编码关联度也相近。
这里的图片按32x32的大小划分,所以是得到7x7个patch。
Transformer Encoder
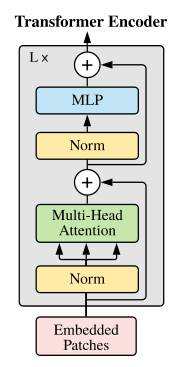
Transformer Encoder其实就是重复堆叠Encoder Block L次:
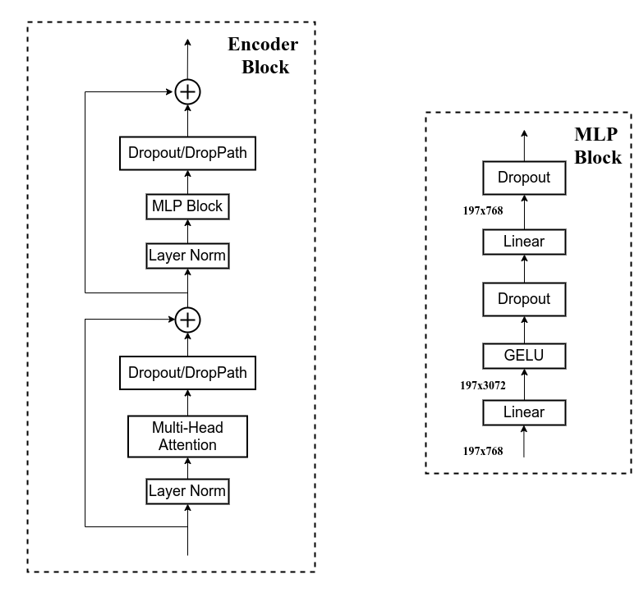
Layer Norm,这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理
BN是取不同样本的同一个通道的特征做归一化;LN则是取同一个样本的不同通道做归一化。
Multi-Head Attention,这个结构之前是在Attention Is All You Need这篇文章中提出
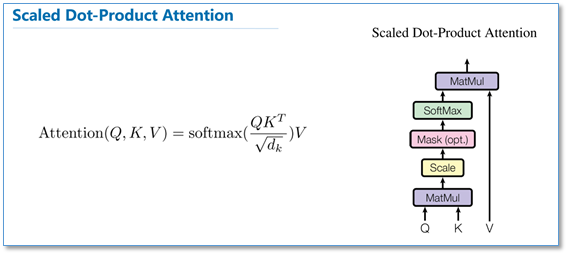
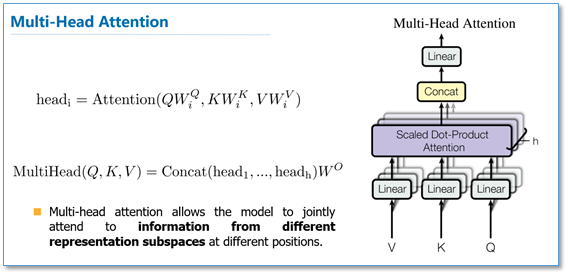
我感觉这原文当中这两个图比较抽象,大概讲下我的理解:
Self-Attention :

首先把输入的token通过Input Embedding映射为,然后通过3个可变换矩阵(这三个参数是可训练的,并且是共享的)计算得到对应的Q,K,V。
- q代表query,后续会去和每一个k进行匹配
- k代表key,后续会被每个q匹配
- v代表value,从a中提取得到的信息,可以理解为相关性权值
Q和K相乘,得到是查询向量和各个对应的键向量的相关性(匹配度),是 n×n 的矩阵。
除以根号dk,再通过SoftMax得到缩放后的attention score,再与V相乘,得到加权和作为最后的输出。
点乘操作可以写成矩阵乘法,实现计算并行化,因此计算速度会快很多。
Multi-Head Attention :
Q,V,K分别通过n次线性变换得到n组Q,K,V,这里n对应着
对于每一组通过Self-Attention得到
拼接所有的,然后将其线性映射得到最终输出。
Dropout,减少过拟合,保证模型的稀疏性
MLP,如图所示,就是全连接+GELU激活函数+Dropout
MLP Head
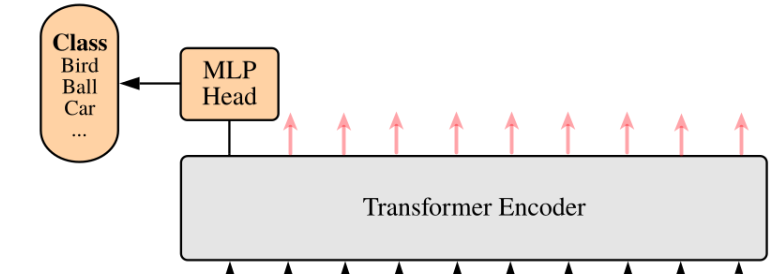
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的。
所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中提取出[class]token对应的[1, 768]。
接着我们通过MLP Head得到我们最终的分类结果。
MLP Head 由 Linear+tanh激活函数+Linear组成。
整体网络的内部结构:
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!