Advancing ViT in Remote Sensing
Advancing ViT in Remote Sensing
Introduction
论文题目 :Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model
论文地址 :https://arxiv.org/pdf/2208.03987v2.pdf
论文出处 :arxiv
代码实现 :https://github.com/ViTAE-Transformer/Remote-Sensing-RVSA
Idea
提出了一个为Remote Sensing领域定制的大型ViT模型,有1亿个参数。
提出了一种新的旋转可变大小窗口注意力机制(RVSA)来替代Trasnsformer中的全注意力机制。
检测任务的实验证明优于所有最先进的模型,在DOTA-V1.0上实现了81.16%的mAP。
Detail
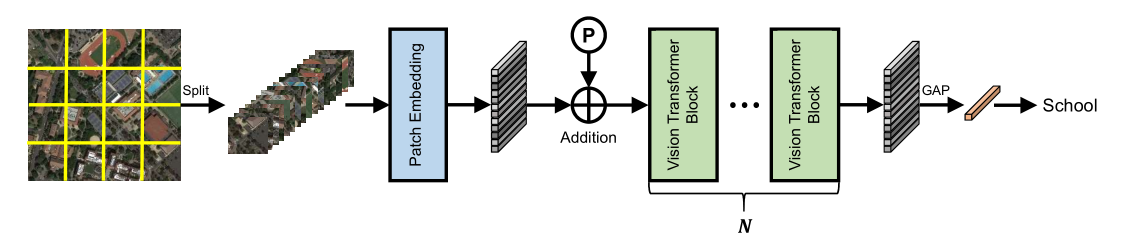
本文与前面一些旋转目标检测文章的主要不同点就在pretrain和backbone上。
Pretrain–MAE
本文当中的ViT和ViTAE都是基于一种自监督学习的方法MAE去进行预训练的,使用的数据集是MillionAID(无label)。
MAE 2022 CVPR Kaiming He
在预训练期间,对输入图像的patches按照预先指定的mask ratio进行随机掩码。
没有被掩盖的patch经过encoder生成visual token ; 被掩盖的patch不会经过encoder,而是按照原先patch的顺序填充mask token。
然后按顺序排列好的visual token和mask token经过decoder,decoder以像素为单位去生成原始图像。
预训练之后,decoder被丢弃,encoder被应用于未损坏的图像,为识别任务生成表示。
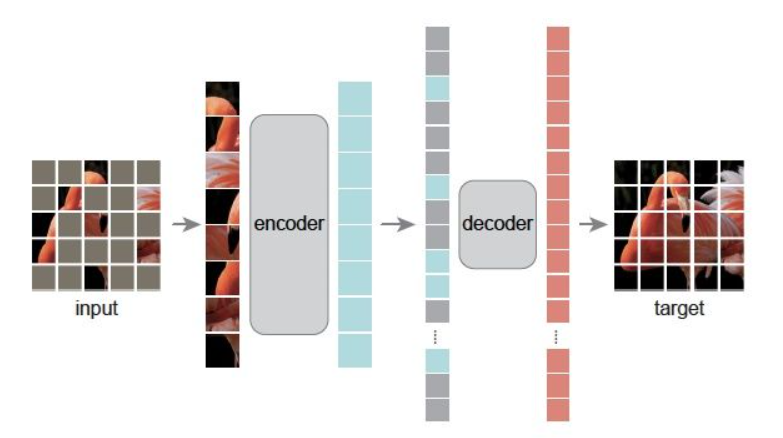
在本文的介绍当中,是所有的patch都会经过encoder生成visual token,然后按照mask ratio的比率去随机丢弃token(token dropping)。
Backbone–ViT 和 ViTAE
主要区别就在于堆叠的Vision Transformer Block结构上。
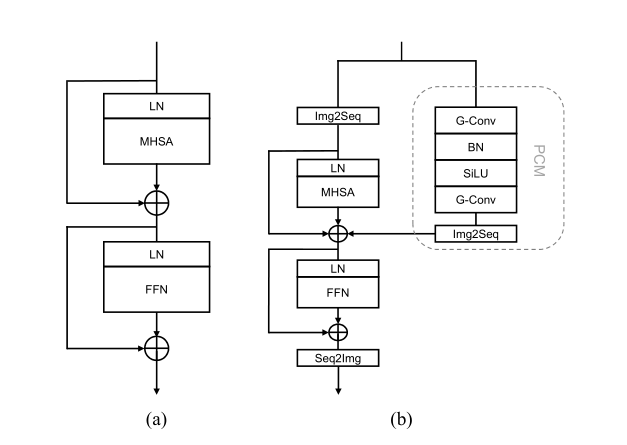
ViT的Block就不过多介绍,很经典的Layer Normalization + Muti Head Sel Attention + Feed-Forwad Network(MLP) + Add
ViTAE,是作者之前的成果,论文中放的图片也是,
主要就是增加了一个并行卷积分支(Parallel convolution branches,PCM)
Group Conv + Batch Norm + SiLU + Group Conv
本文的原话:MAE中关键的设计就是token dropping,但是这个操作会破坏token之间的空间关系,所以作者设计了ViTAE的Block。
原理是说结合了归纳偏置,具体是怎么回事可能还得看ViTAE的原文
Attention–RVSA
在本文中作者使用了旋转可变大小窗口注意力机制((Rotated Varied-Size Attention,RVSA)替换了原先的多头注意力机制(MHSA)。
RVSA基于作者之前的成果(Varied-Size Window Attention,VSA)。
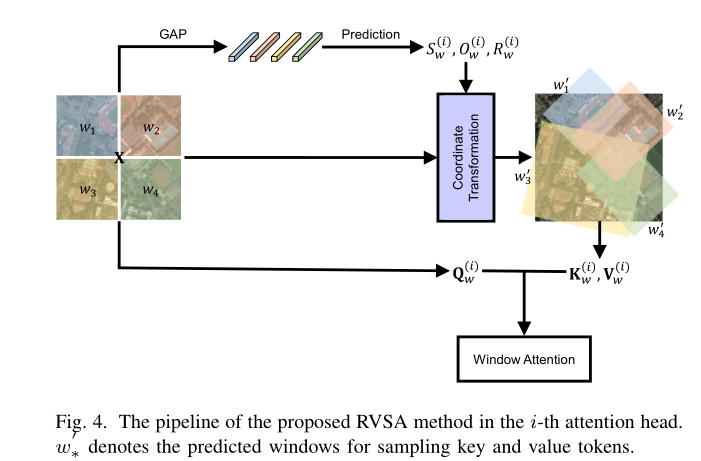
Varied-Size Window Attention又是基于Window-base attention(思路源于Swin-T),以固定大小的窗口作为初始化,并从这些窗口提取Qw,对于Kw和Vw,通过输入Xw去预测目标窗口的偏移量o和比例s去得到。
对着论文比较好讲,先讲Window-base attention的s,
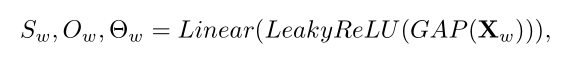
Coordinate Transformation
该模块主要是就是坐标变换,
对于VSA:

对于RVSA:
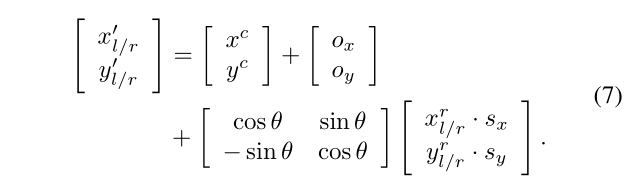
一些细节
最佳Mask Ratio通过Linear probing setting和 Fine tune setting实验获得,为0.75时达到最佳性能。
Window-base attention的初始化分割, 通过实验,在DOTA和DIOR-R数据集上s均取7能达到最佳性能。
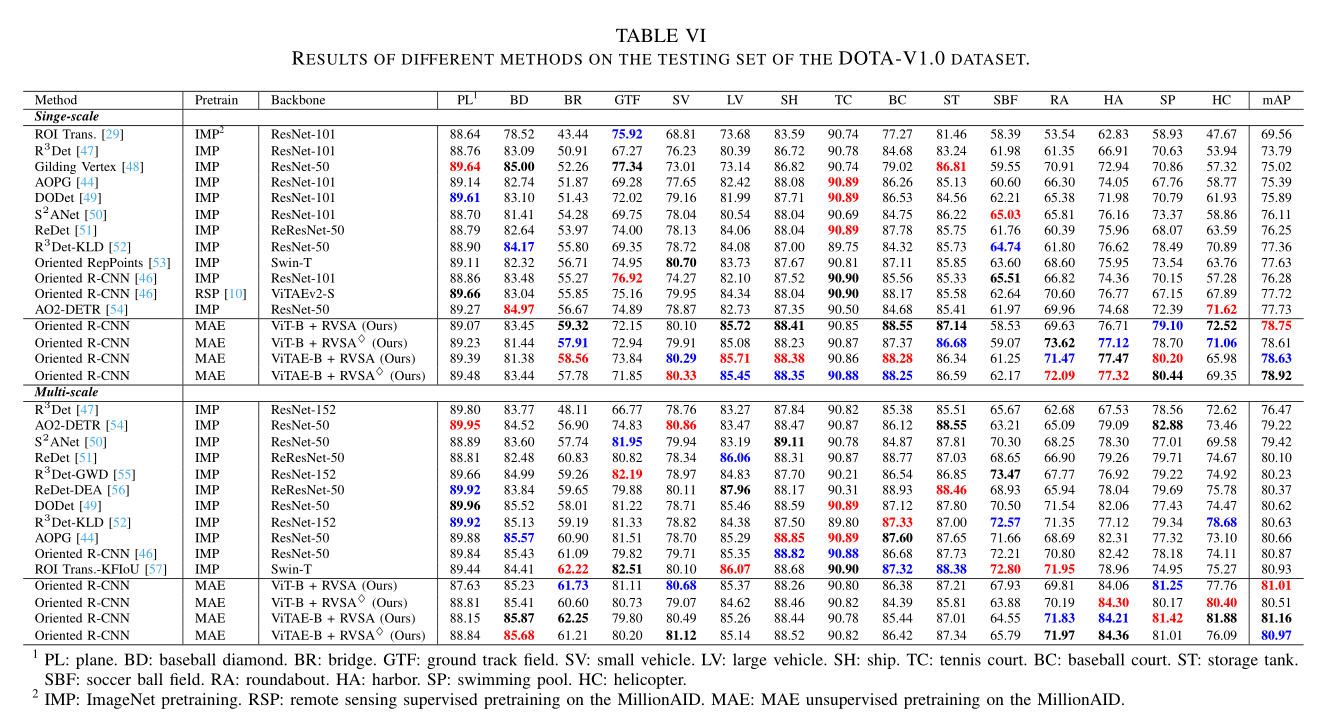
Result
作者使用的大的网络框架是Oriented-RCNN,主要对比pretrain和backbone
黑、红、蓝色依次标注是该类别的acc1、2、 3名
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!