2022-09-27-组会
2022-09-27-组会
Orthogonal Transformer
NeurIPS’ 2022: https://nips.cc/Conferences/2022/Schedule?showEvent=55394
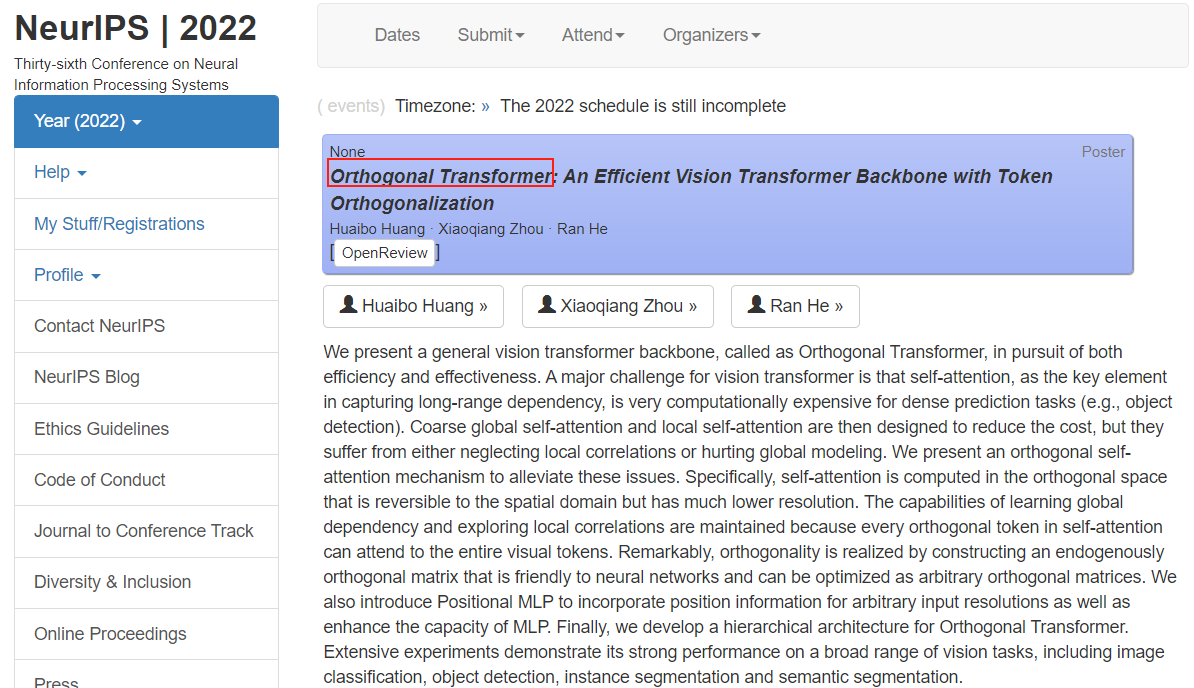
如果后续这篇文章放到arxiv上了,我会再读一读。
O-ViT:Orthogonal Vision Transformer
2022年2月16日: arXiv:2201.12133v2
这篇文章可以学习借鉴的地方不多:
=>它是 纯数学理论上的优化 ,通过正交流形在黎曼空间和欧几里得空间中的转换,保证特征图的失真度较小,进而保证计算过程的置信度
文章中反复提到一些几何流形、正交群、李代数等概念,需要有相当好的矩阵论和抽象代数的基础才能理解,缺少一般Deep Learning的优化思想,我认为只适合套用。
=>该 文章代码未开源 ,难以学习及复现(套用都套用不了)
Idea
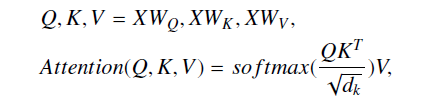
- ViT中Self-Attention的线性变换会给特征空间带来尺度模糊性
- Softmax函数存在梯度消失的风险
前人有将流形优化用在R-NN和C-NN上,也有人利用正交矩阵的范式稳定性来缓解梯度爆炸和消失的问题,因此作者想试试将这个应用在ViT上。
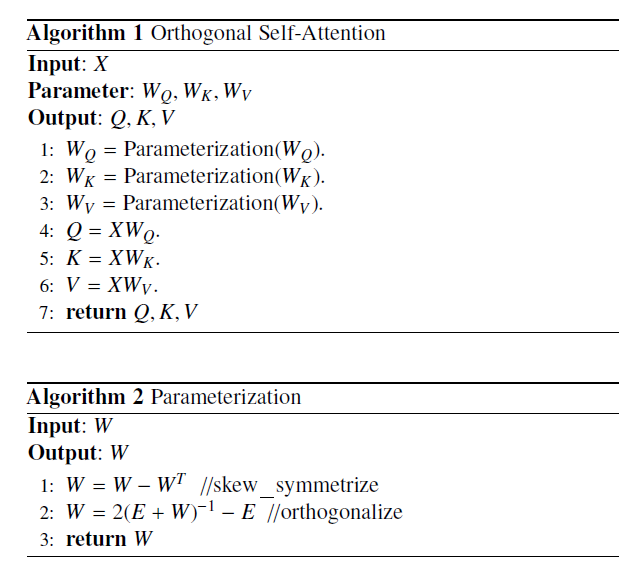
O-ViT Architecture
实际上,有用的就是两行伪代码:
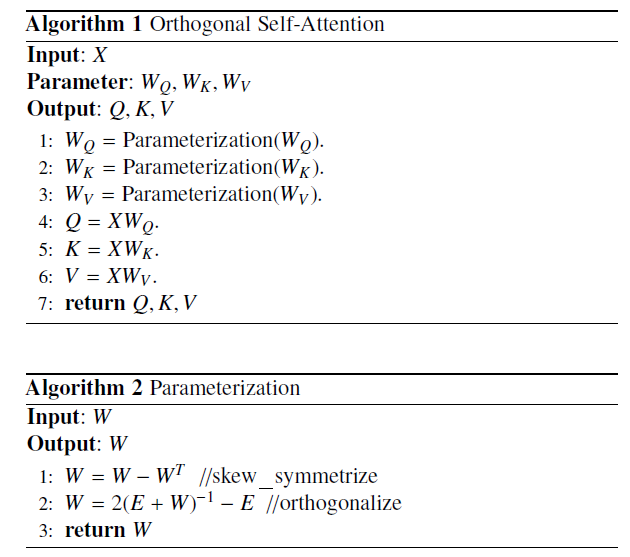
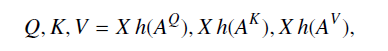
通过构造斜对角矩阵过渡,来实现对的正交约束。
这就必须要求原都是正交矩阵,这是怎么保证这三个权重矩阵初始化时就是正交矩阵的?
附录中含有数学证明:
Swin TransFormer
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!