Generalized Focal Loss
Generalized Focal Loss
Introduction
论文题目 :Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
论文地址 :https://arxiv.org/pdf/2006.04388.pdf
论文出处 :2020’NeurIPS
代码实现 :https://github.com/ViTAE-Transformer/Remote-Sensing-RVSA
Idea
one-stage的检测器最后都会归于两个子任务,即分类和定位。分类通常用Focal Loss,而定位通常用IOU Loss。而在近年的one-stage论文中(FCOS),趋势是引入额外的分支centerness来评估检测框的定位质量。但是这样会带来两个问题(classification score 和 IoU/centerness score 训练测试不一致和bbox regression 采用的表示不够灵活,在建模复杂场景下的具有不确定性),作者尝试解决这两个问题,提出了GFL。
基于任意one-stage 检测器上,调整框本身与框质量估计的表示,同时用泛化版本的GFocal Loss训练该改进的表示,可以实现无cost涨点(一般1个点出头)AP。
Detail
Question
1.classification score 和 IoU/centerness score 训练测试不一致
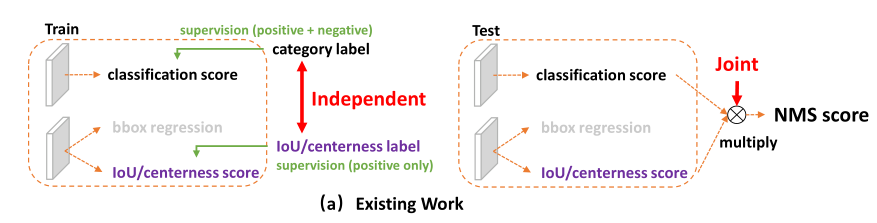
用法不一致。
训练的时候,分类和质量的评估是分离的,但测试的时候却又是乘在一起作为NMS score排序的依据,这个操作显然没有end-to-end,必然存在一定的gap
对象不一致。
Classification : 得益于Focal Loss ,可以计算少量正样本和大量负样本的classification score,并一起成功训练.
Localization: 在使用IoU/centerness score时,却是只针对正样本的score训练(正负样本的score都会计算)。
在做NMS score排序的时候,所有的样本都会将分类score和质量预测score相乘用于排序。
由于有大量的负样本,就很有可能出现以下情况:
NMS score: 负样本(分类score相对较低 * 高质量定位score)> 正样本(分类score不够高 * 质量score较低)
出现NMS score排序后,负样本排在正样本前面的不合理现象,导致真实的正样本被NMS过滤。
本文提出的联合分类和定位表示使得分类和定位得分保持一致(图b绿色的点)。
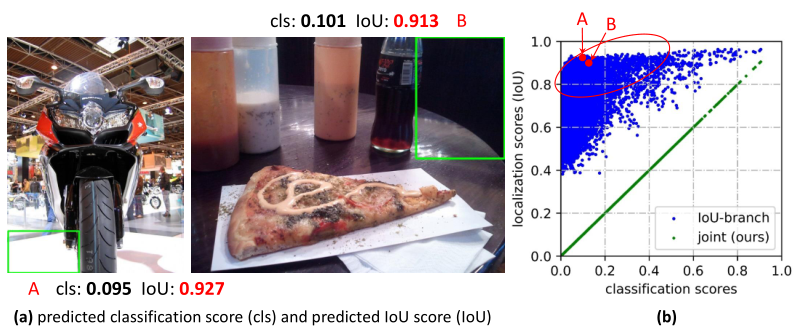
可以看出来,作者在对监督训练和one-stage的端到端理念有很深的见解。
2.bbox regression 采用的表示不够灵活,在建模复杂场景下的具有不确定性
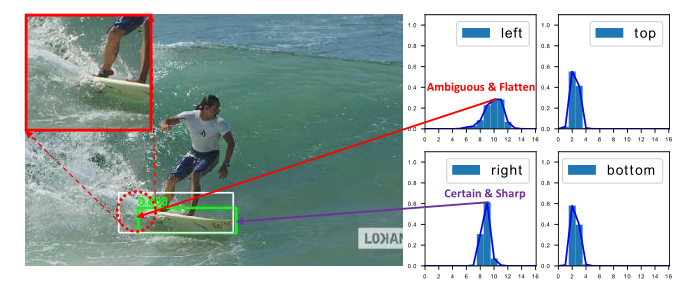
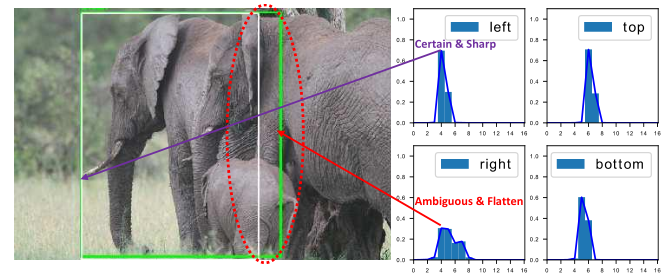
白色的是真实框,绿色的是预测框。可以看到图中的帆板边缘或被遮挡的大象边界,其实都很难去界定一个精确的位置。
在这时候,传统的单一Dirac delta分布建模并不符合实际的情况。
作者提出的一般分布,针对模糊和遮挡的物体采用扁平的分布来表示,清晰的物体采用尖锐的分布表示。
Method
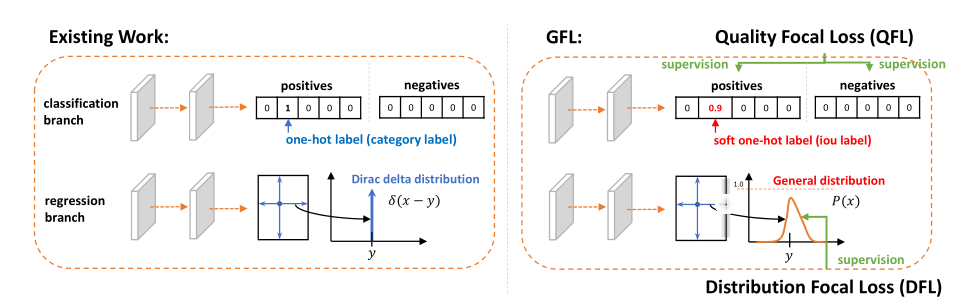
针对离散的{0, 1}标签,本文classifcation 联合 IoU score变为了产生0~1的值作为相应类别的质量评估,将其扩展采用QFL来进行训练;
QFL
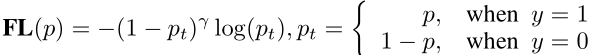
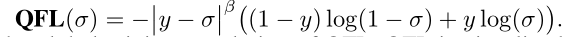
对比可以发现,把离散的0,1分布改为了为0~1的质量标签,然后把调制因子外面括号换成了绝对值,形成了标准的交叉熵函数。
DFL
之前的回归的标签当作Dirac delta分布,只做单一概率分布,不够灵活。
假定我们回归的标签 存在最小值 和最大值 。
通过均等划分(简单取:间隔为1)得到离散的集合(这种离散化可以通过softmax实现)
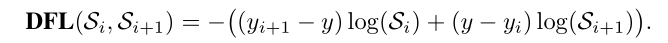
可以理解为DFL以类似交叉熵的形式去优化与标签最接近的一左一右两个位置的概率,从而让网络快速地聚焦到目标位置的邻近区域的分布中去
GFL
统合了QFL和DFL
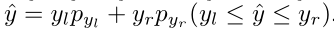
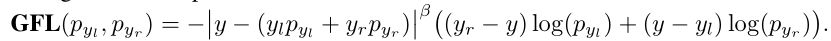
Result
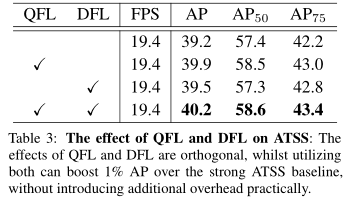
在ATSS上做消融实验:
总体网络对比:
仔细对比对应的网络结构,发现是有涨点的。

本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!