Focal and Global Distillation
Focal and Global Knowledge Distillation
Introduction
论文题目 :Focal and Global Knowledge Distillation for Detectors
论文地址 :https://arxiv.org/pdf/2111.11837.pdf
论文出处 :2022’CVPR
代码实现 :https://github.com/yzd-v/FGD
Idea
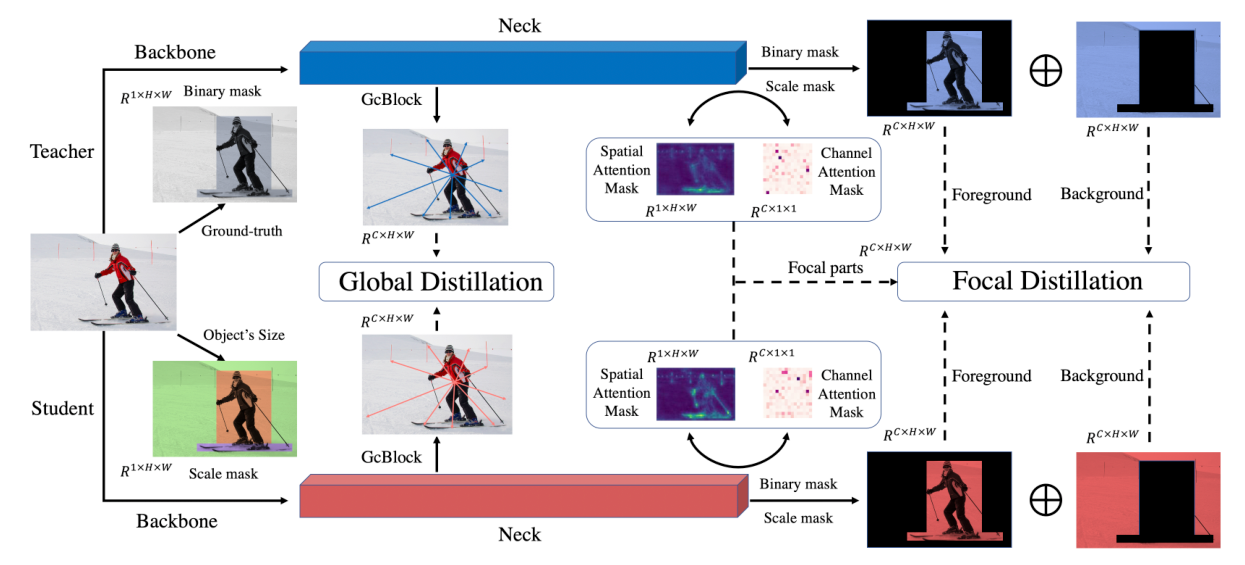
在目标检测中,Teacher和Student的特征在不同的区域由很大的差异,特别是在前景和背景上。如果同等的提取它们,特征图之间的不均匀差异将对提取产生负面影响。因此作者提出了焦点和全局蒸馏FGD,所有损失函数仅根据特征计算,因此可以适用于各种检测器。
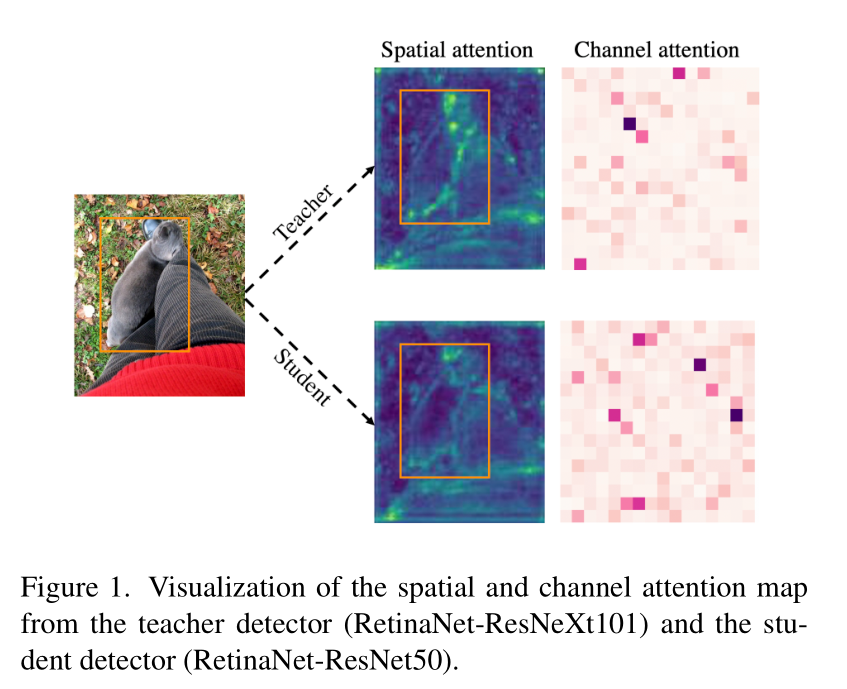
焦点蒸馏分离前景和背景,迫使学生关注教师的关键像素和通道,全局蒸馏重建了不同像素之间的关系,并由教师传递给学生以补偿焦点蒸馏丢失的全局信息。
Detail
Feature Distllation
参考文章1:[2015’ICLR]-FitNets:Hints For Thin Deep Nets
参考文章2:[2019’ICCV]-A Comprehensive Overhaul of Feature Distillation
Logits Distllation引入了一个模型压缩框架(Teacher-Student),该框架通过将深度网络(Teacher)的集合压缩为具有相似深度的学生(Student)网络。但是高性能的Teacher输出的Soft Target与Ground Truth并没有显著差异,这就会限制蒸馏效果。
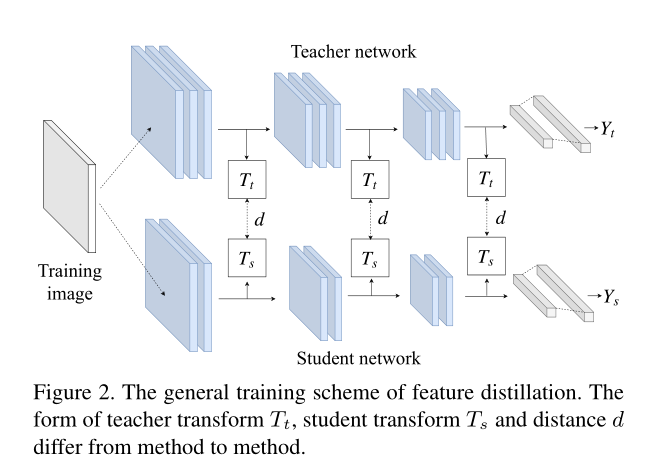
为了更好的利用Teacher网络中包含的信息,可以使用Feature Distllation。
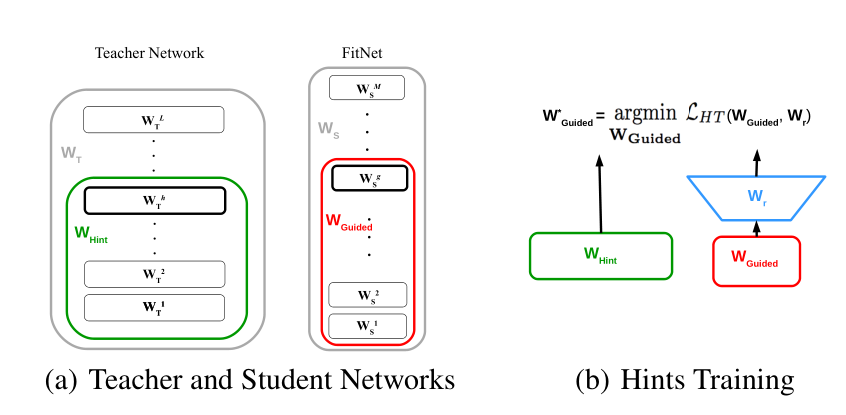
hint layer&guided layer
选择Student的一个中间层(这层称为guided layer),去学习Teacher的一个中间层(称为hint layer)的output,也就是guided layer需要正确预测hint layer的输出。
hint layer 高宽和通道数
guided layer 高宽和通道数
regressor
考虑到Teacher通常比Student更高更宽,所选的hint layer可能比guided layer具有更多输出,因此给guided layer添加一个regressor,使guided经过regressor后其输出与hint layer的大小一致。(自适应宽高)
全连接
regressor的weight矩阵参数:
反卷积
regressor的kernel大小确定: ,
用个大小为的kernel对guided layer做反卷积。
regressor的weight矩阵参数:
关于特征蒸馏的位置选取,FitNets是使用的是任意中间层的末端输出作为蒸馏点。
Training Scheme
特征蒸馏提取的损失可以被定义为:
Teacher transform : 对Teacher的hint layer层输出做变换。
Student transform : 对Student的guided layer层输出做变换。
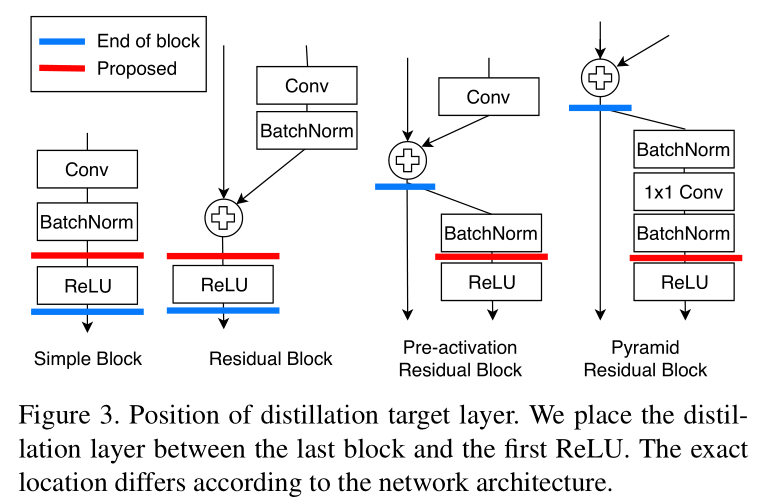
Distillation feature position:改变特征蒸馏的位置选取。
比如在激活函数前进行蒸馏:
Distance function:衡量特征提取的损失函数通常采用。
以上是Feature Distllation的提出及归纳,因为guided layer和hint layer的维度不一致和特征图的差异性,并且引入了特征提取的损失,后续在此上有很多文章可做。
Focal and Global Distillation
把特征蒸馏损失按CWH维度拓展:
Focal Distillation
这里所谓的Focal,是让Distillation更多注意gt的bboxes。
Binary Mask
首先设置一个Binary Mask来分离背景和前景。
其中表示ground-truth的bboxes,是特征图中的横纵坐标,如果映射回原图落在ground-truth中,则,否则为.
Scale Mask
然后为了平衡前景和背景的损失,使其被平等对待,设置一个Scale Mask:
可以看出来其实就是面积比的倒数作为权重。
其中和表示ground-truth的宽高。(如果有像素被多个gt bboxes重叠,选择最小的框来计算S)
Attention Mask
借鉴了2017’ICLR:pay more attention to attention该文章提出了注意力蒸馏。
然后把像素和通道分离,做Attention Mask => 分别为
这就是提出的问题图中的spatial attention map和channel attention map。
先求、输出的绝对值的平均值
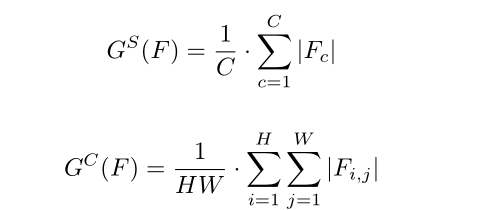
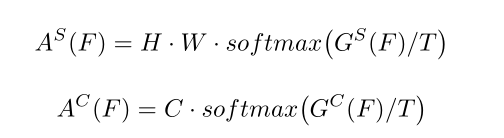
Focal Distillation loss
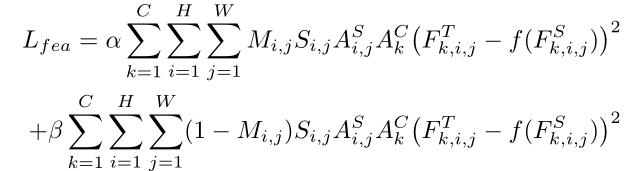
前半部分是前景,后半部分是背景。
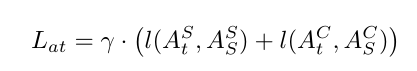
用L2 loss衡量特征图蒸馏损失,用L1 loss衡量注意力蒸馏损失。
可以认为焦点蒸馏 = 特征蒸馏 + 注意力蒸馏
Global Distillation
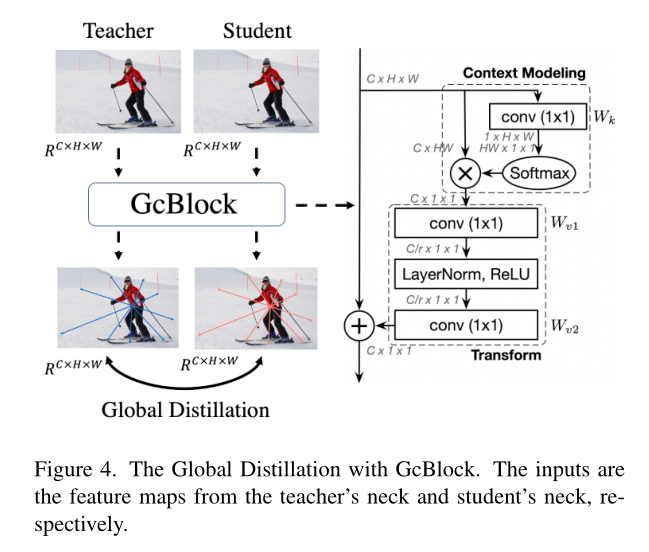
把GCNet提出的GC-Block(Global Context Block)模块,应用到知识蒸馏当中。
GC Block可以理解为一个适用于求目标检测任务的图像attention map的模块。
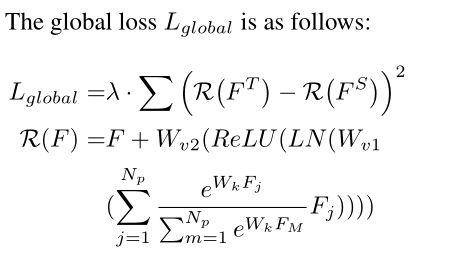
Overall loss
Result
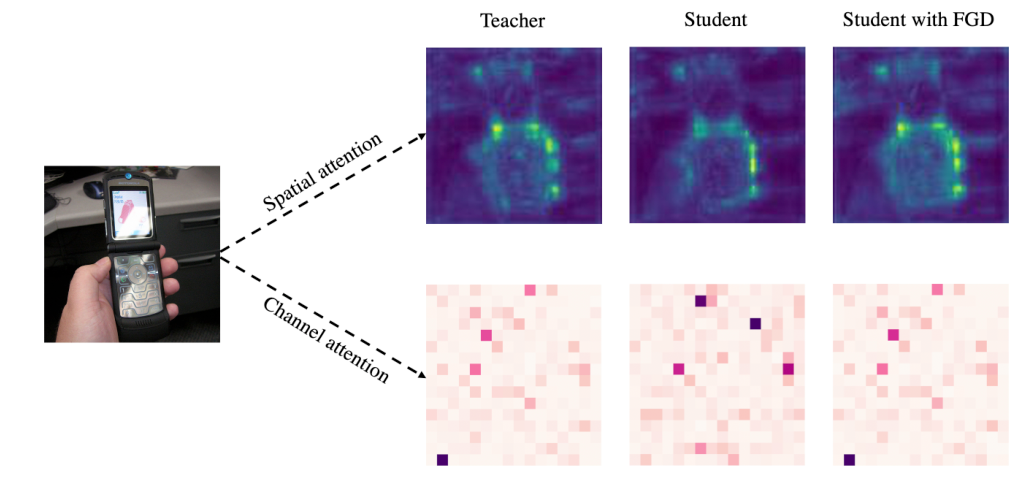
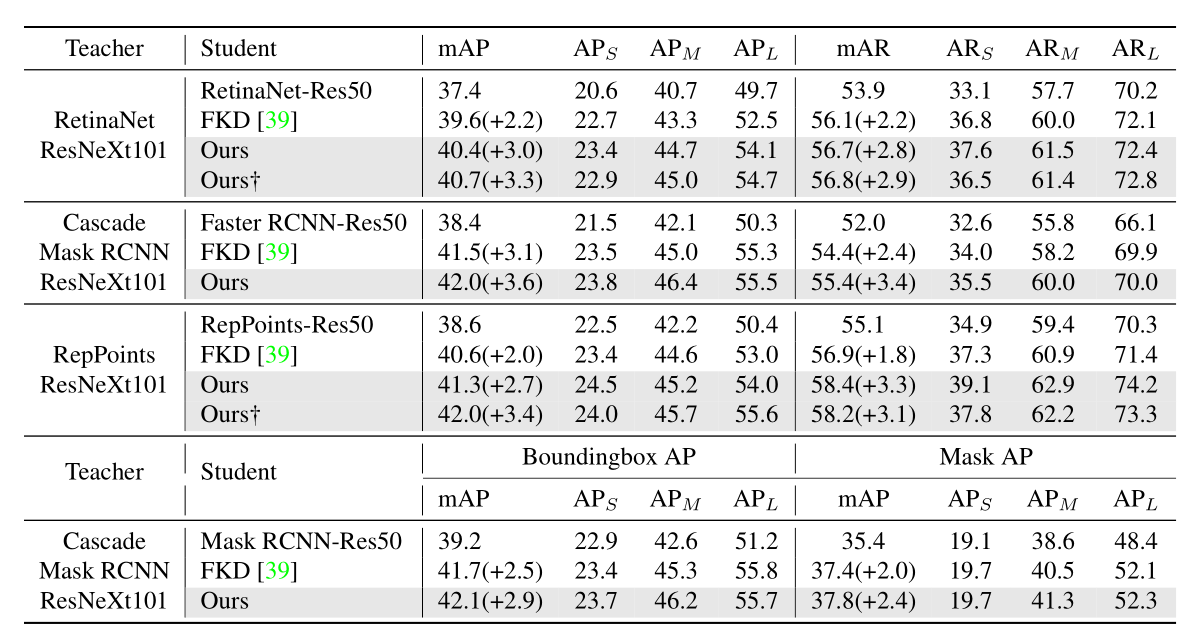
总结
可以看到在最新的研究中,又把特征图蒸馏、注意力蒸馏按空间角度划分了像素,通道。
GC Block是一个很好的模块,用于提取目标检测任务中的attention map。
所以说总的来看,Feature Distllation的可以改进和切入的角度有很多。
而且我认为,作者的这个思路肯定不是一蹴而就的,而是在做实验的过程中不断调整的。
todo: 一定要读一下GC Net。
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!