RBox
RBox
Introduction
论文题目 :Few Could Be Better Than All: Feature Sampling and Grouping for Scene Text Detection
论文地址 :https://arxiv.org/abs/2203.15221v2
论文出处 :2022’CVPR
代码实现 :Not released.
Idea
作者认为没有必要对所有像素的relationship进行特征学习。因为前景目标只占场景图像中的几个小而窄的区域。作者首先采样并收集与前景高度相关的特征,然后使用Tansformer建模来分析采样特征之间的关系,使得前景特征能被正确的分组。并且这样做可以免去anchor generation、NMS等后处理。

Detail
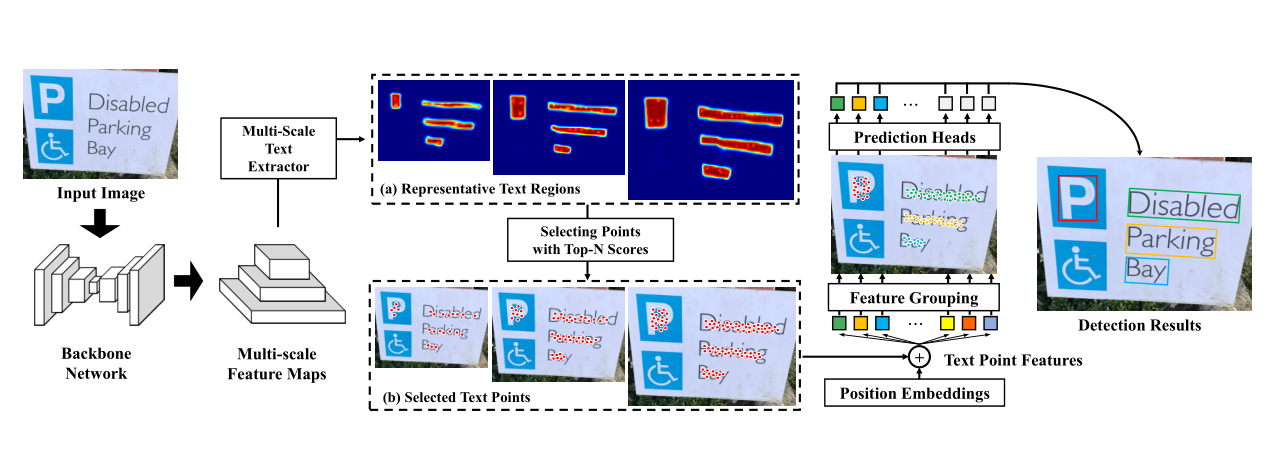
首先通过一个Backbone network(Backbone: ResNet50 + neck: FPN),得到多尺度特征图,然后送入MultiSale Text Extrator中,对多尺度特征逐层的进行以下两个步骤:a) 预测提取代表性的文本(前景)区域; b) 在前景区域进行像素级的预测置信度得分confidence scores,选取Top-N个点作为与前景高度相关的特征。然后送入Tansformer模块[具体进行位置编码(Position Embedding),然后送到Transfromer Block)]进行关系建模=>特征分组,让每一组对应一个实例。最后送入预测head回归出检测框,并进行分类。
Backbone
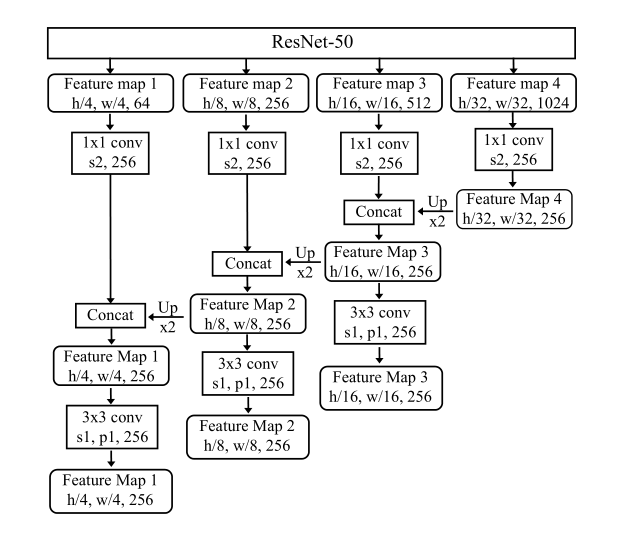
主要选取的是P2-P4 (1/4、1/8、1/16)进行特征采样。
Multi-Scale Text Extractor
CoordConv Layer
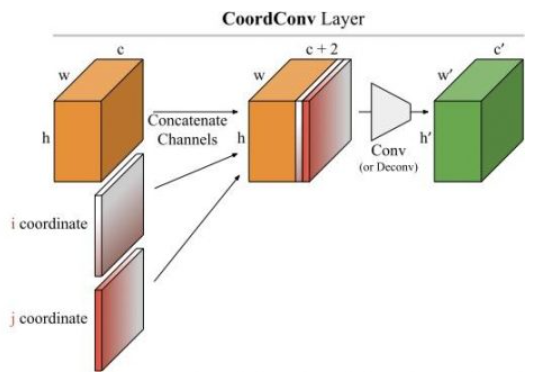
将每个特征图与两个额外的归一化坐标(x, y)通道连接起来,以引入位置信息。
Constrained Deformable Pooling
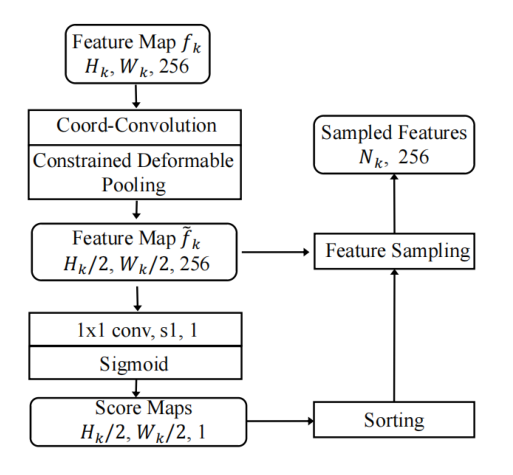
作者设计了一种独特的下采样方式,即在下采样时增加了一个可学习的尺度参数用于约束预测的偏差,保证不近邻的特征区域不会相互影响,即只合成较小范围内的文本区域的特征。
Scoring Net
用sigmoid激活函数来二分类,以生成前景文本区域的置信度得分confidence scores。然后对这些score排序选择每个尺度下前TopN个点,送入Transformer。
Feature Grouping
作者在论文中没有具体说是如何利用Tansformer做到给特征进行分组的。
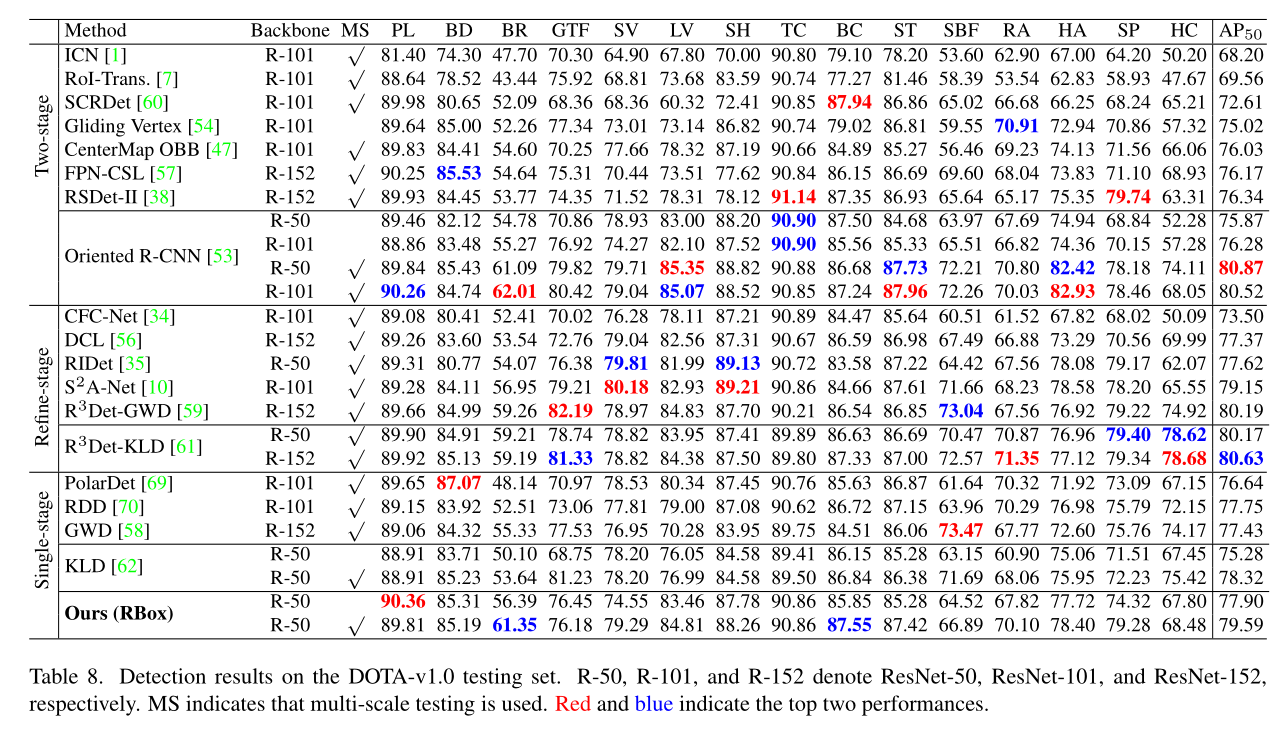
Result
截了一个在DOTA数据集上的实验对比:

总结
看着简单,但是还有有几个点是值得注意的:
首先,作者仅仅只是把Transformer用于对特征点之间的关系建模上, (只用于一个子任务)这是很值得注意的。根据我以往读过的Tansformer目标检测相关的论文,之前要么就是把Swin Transfomer作为一个backbone,处理出特征图,然后送入后续head进行处理; 要么就是一整个网络用Tansformer结构.
只在预测出来的前景区域做Transformer,可以大幅度减少Transfomer因为大量参数带来的计算量。减少了背景噪声带来的影响,从而提高的检测精度.
整个网络结构避免掉了anchor,可以无需通过复杂的后处理(anchor generation,NMS等)而准确获得bbox。
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!