H2RBox
H2RBox
Introduction
论文题目 :HORIZONTAL BOX ANNOTATION IS ALL YOU NEED FOR ORIENTED OBJECT DETECTION
论文地址 :https://arxiv.org/abs/2210.06742
论文出处 :arxiv 2022.10
代码实现 :https://github.com/yangxue0827/h2rbox-mmrotate
Idea
现在很多目标检测数据集的annotation都是基于水平边界框的注释,但是水平框数据集不能直接用于旋转检测器的训练,这就导致现成的数据集和不断增长的旋转目标检测需求之间存在gap。因此作者提出了一种HBox-to-RBox style method(H2RBox),使用水平框进行弱监督学习,并且采用无监督学习辅助修正尺度和空间上的一致性,来预测对象角度。
SKU110K (零售场景数据集, 2019) = > SKU110K-R (2020)
DIOR (航空数据集 2020) => DIOR-R (2022)
这两个数据集一开始是水平框标注的,然后后面为了做旋转目标检测而特地使用旋转框重新标注。
Detail
作者实验发现,通过一些用水平框弱监督的实例分割模型(BoxInst, BoxLevelSet),可以轻松获得分割掩码Mask,然后通过掩码的最小外接性,可以轻松获得最终的旋转框。作者称这种方法为HBox-Mask-RBox style methods.

可以看到这个model也是一个二阶段的任务,而且第一阶段是实例分割,
如果直接引入实例分割,会带来以下问题:
- 分割质量很可能对背景噪声敏感
- 在对象拥挤等复杂场景中,会严重影响后续RBox的检测步骤.
- 实例分割的计算成本往往更高,导致整个检测过程耗时更长。
基于以上几点,作者提出了一种HBox-to-RBox style method(H2RBox)。想要跳过实例分割这个步骤,来构造一个HBox-to-RBox paradigm.
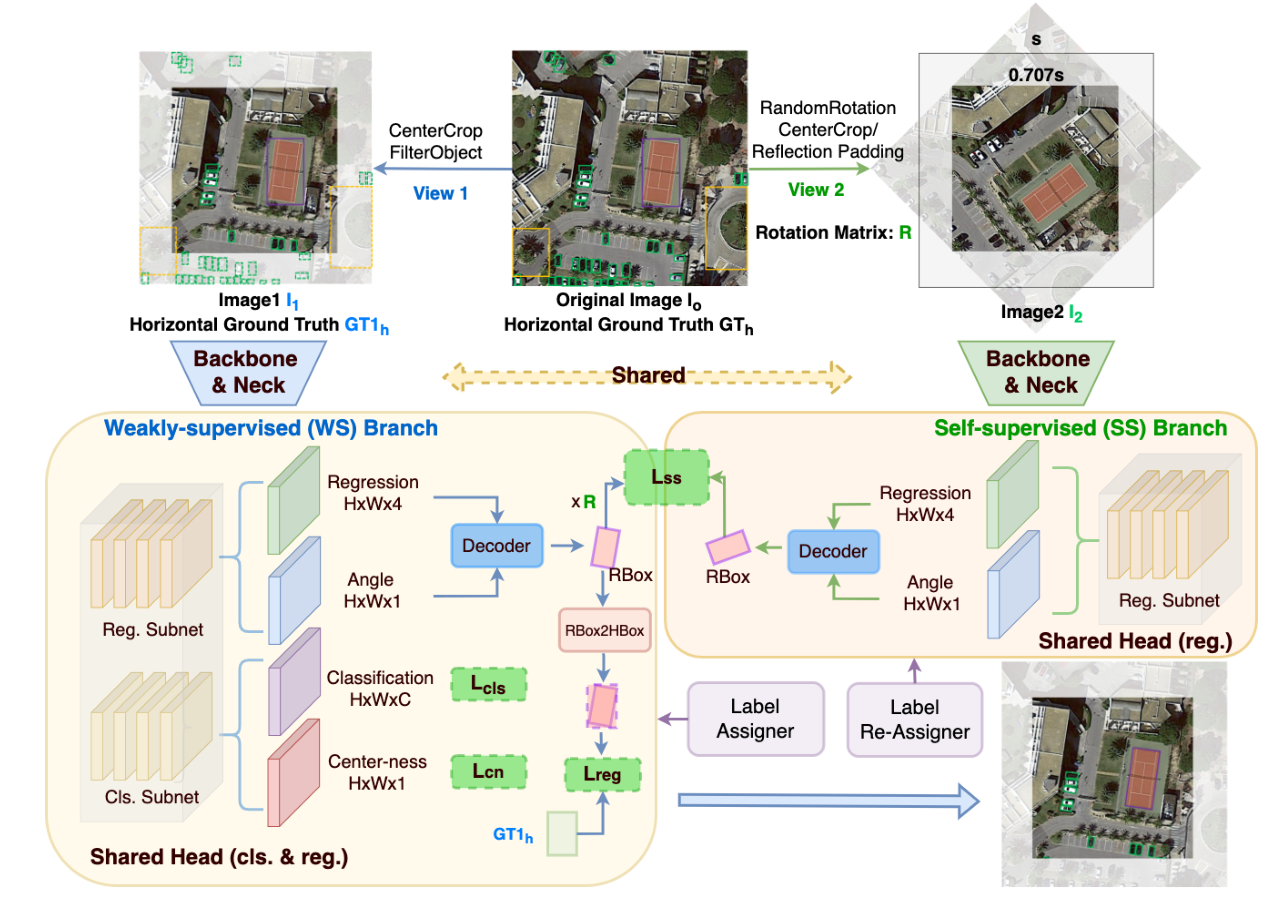
具体来说:
首先经过WS分支中的FCOS网络,得到预测的RBox
然后把输入的水平图像旋转一个随机角度,经过SS分支,然后同样回归得到子网络(FCOS)预测的RBox
然后开始计算LOSS
: FCOS网络中的分类Loss
: FCOS网络中的center-ness loss,通过将class score与center-ness相乘后作为最终该预测框的score,从而降低了那些远离object中心点的预测框的权重,并进行NMS,去掉一些远离object的低质量检测框。
: 使用H2RBox的外接矩形与GT的HBox进行Loss计算.
作者认为在理想情况下,WS分支的RBox的外接矩形和GT的HBox是高度重叠的。
WS分支的RBox * Rotation Matrix后,与SS分支的RBox进行Loss计算。
这个就是作者说的通过学习两个分支,不同视图的RBox的一致性(包括尺度和空间),以消除undesired cases.
测试阶段只涉及WS分支.
label re-assignment strategies (label at location in SS branch 旋转映射回 in WS branch的策略)
简单贴一下Loss
: SoftMax Loss : Center-ness loss : Cross entropy Loss
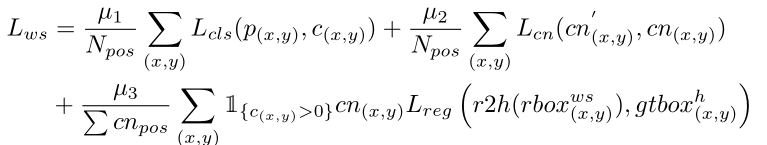
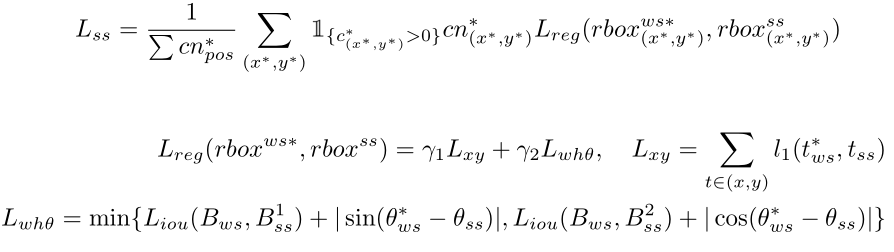
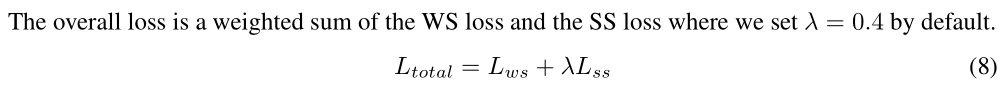
Result
下面两张图对比,说明了但WS的效果不好,这也是为什么作者要引入SS分支。


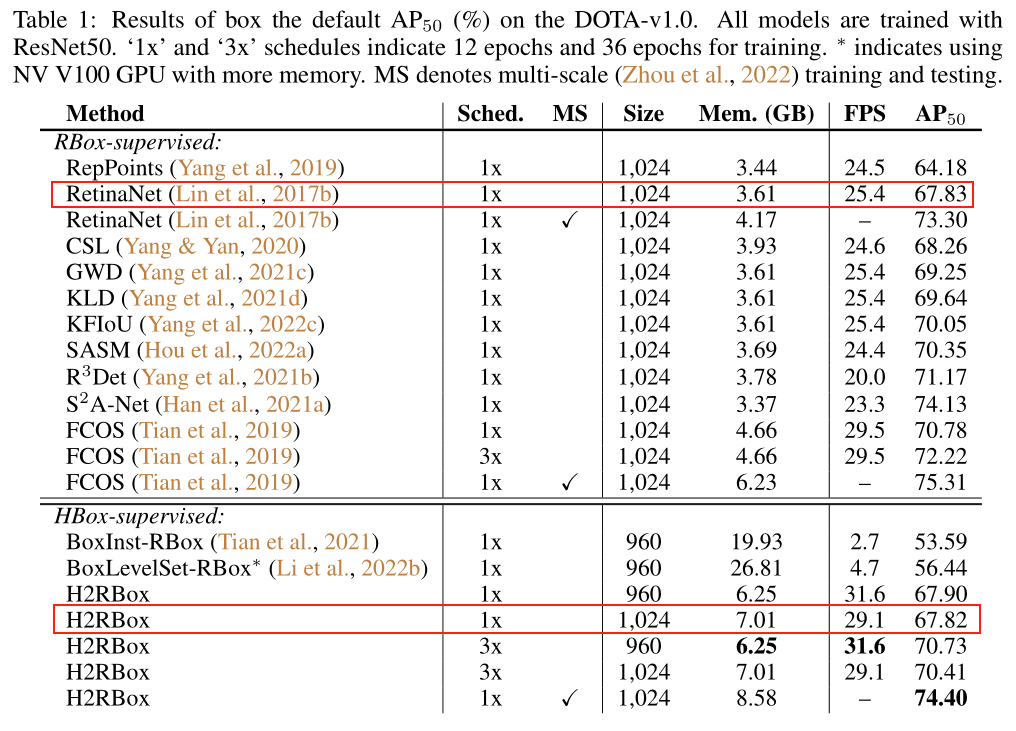
下面是DOTA-v1.0数据集上的性能对比:
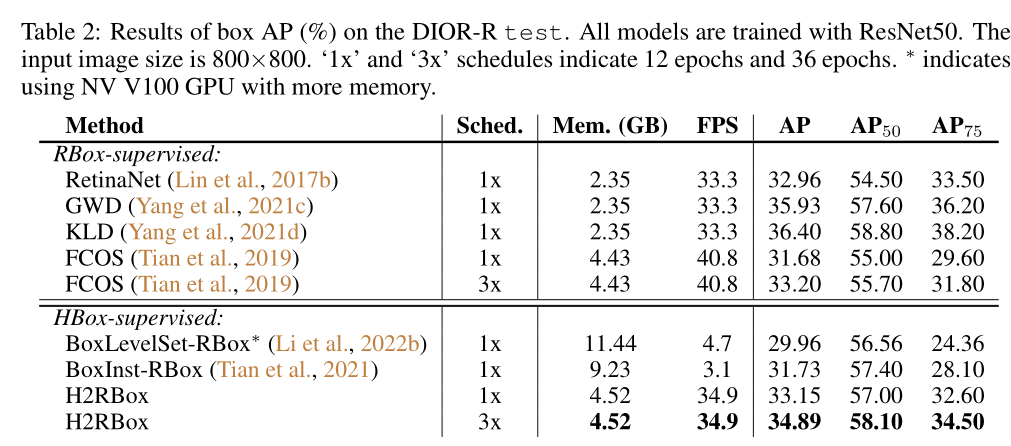
下面是DIOR-R数据集上的性能对比:
总结
不难发现,因为作者的这个方法原创性比较大,没有一个好的baseline,因此效果整体上来说不是很好。
作者的想法很好:怎么样把水平框数据集利用到旋转目标检测上来, more data, more powerful。
但我要研究的重点不是这个方面,因此可能帮助不是很大。
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!