Knowledge Combination to Learning Rotated Detection Without Rotated Annotation
Knowledge Combination to Learning Rotated Detection
Introduction
论文题目 :Knowledge Combination to Learning Rotated Detection Without Rotated Annotation
论文地址 :https://arxiv.org/pdf/2304.02199v1.pdf
论文出处 :2023’ CVPR
代码实现 :https://github.com/alanzty/KCR-Official (目前暂未开源)
Idea
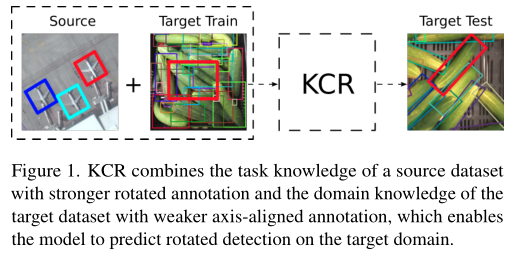
本文提出了一个半监督旋转目标检测框架,使用新的分配过程和投影损失来实现对源数据集和目标数据集的联合训练。
作者相信可以通过与强标记(旋转标记)的源数据集的协同优化来学习在目标域上解码到更精确的任务。
如图1所示,这种方法结合了弱监督学习和迁移学习的优点。
Detail
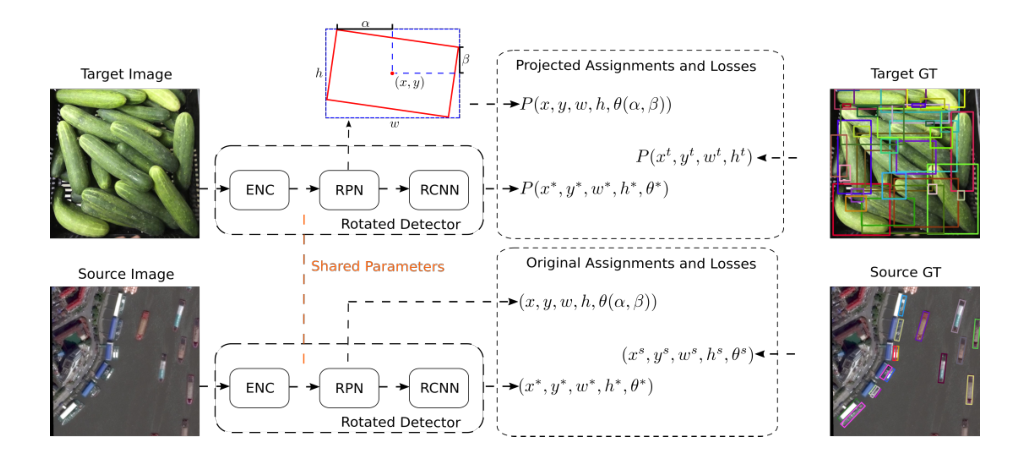
Baseline 是 oriented-rcnn,两个数据集都是在这个网络结构上跑,
我比较好奇两个数据集怎么一起跑,这个作者没提,我个人认为是直接放在同一个文件夹里。
Learning Rotated Region Proposal
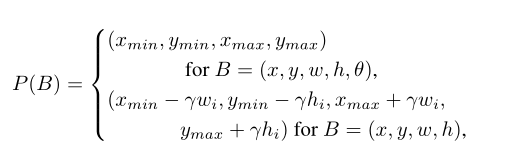
对于Target GT,这里要用一个投影函数P,把它变成旋转框,这里是在GT的基础上加减anchor的宽高*
这里的参数是一个超参数,可以调节
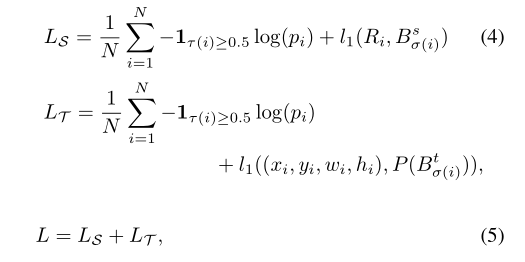
Learning Rotated R-CNN
第二阶段是proposal和GT的匹配过程,作者说测试过后发现false nagative样本比较多,因为是旋转框和水平框进行IoU计算,所以就不算Loss
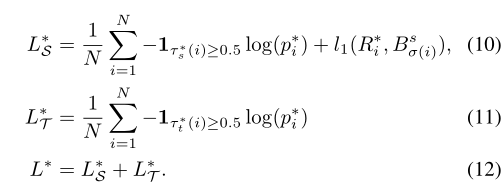
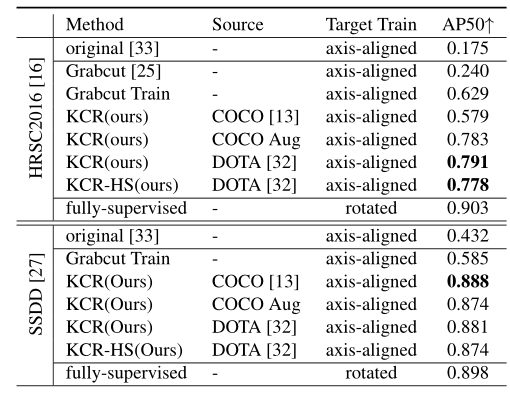
Result
在2080Ti上训练,对硬件要求不高。

HRSC2016数据集少13%
SSDD数据集上比全监督的只少1%,2%
总结
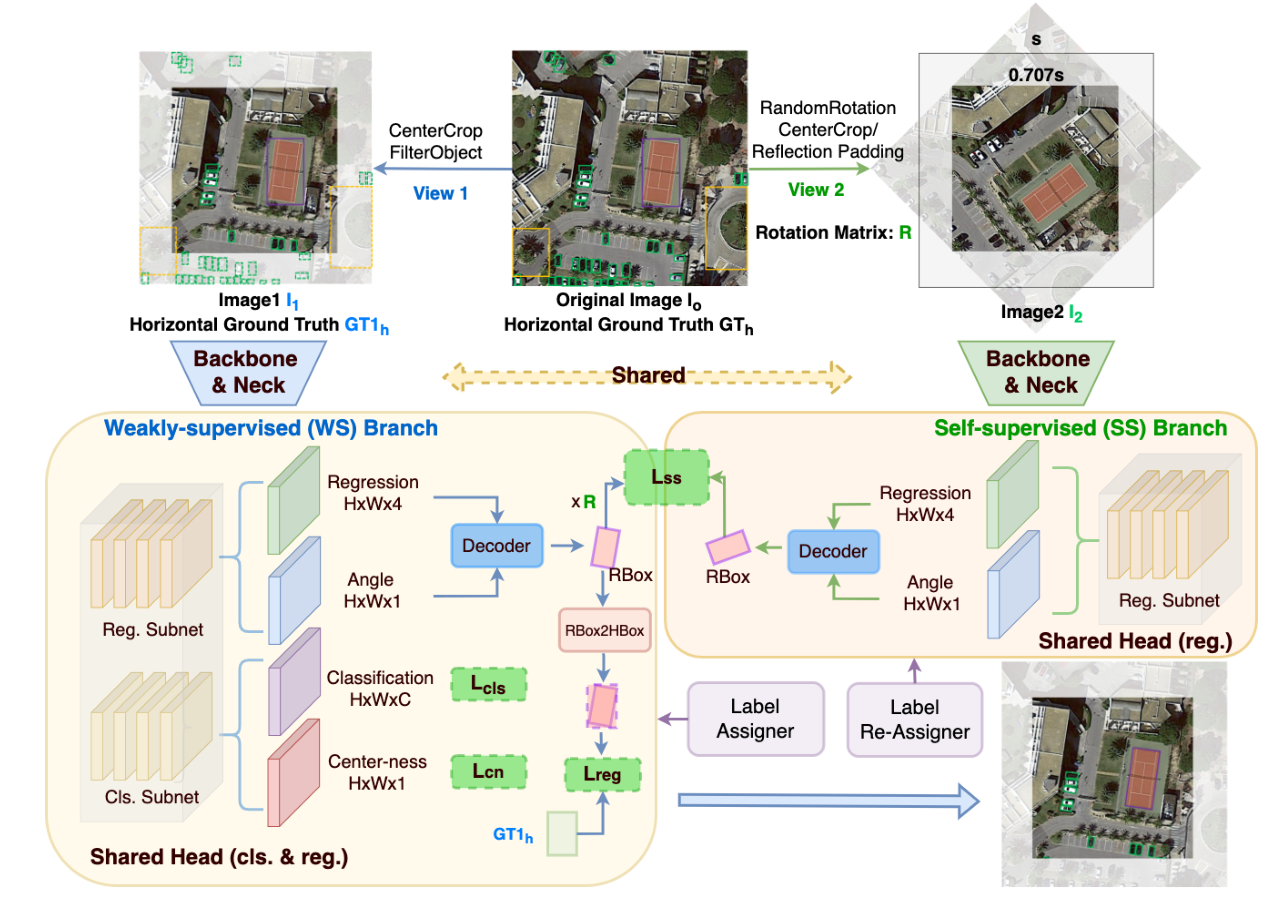
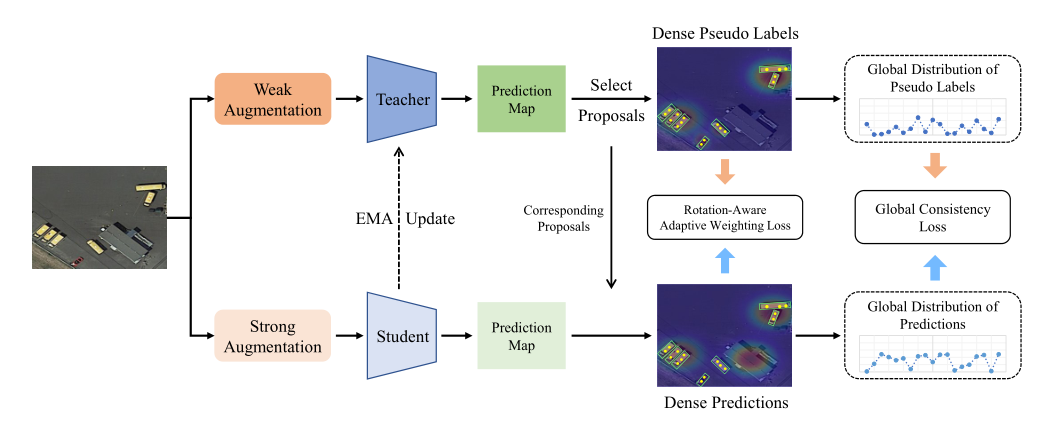
首先提出一个机制,想办法对GT想办法添加旋转角度这个参数:
- H2RBox采用旋转矩阵
- KCR采用投影函数
- SSDD采用的是知识蒸馏
两个分支
然后再在此基础上,调整损失函数。
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!