Knowledge Combination to Learning Rotated Detection Without Rotated Annotation
MixTeacher
Introduction
论文题目 :MixTeacher: Mining Promising Labels with Mixed Scale Teacher for Semi-Supervised Object Detection
论文地址 :https://arxiv.org/pdf/2303.09061.pdf
论文出处 :2023’ CVPR
代码实现 :https://github.com/lliuz/MixTeacher (目前暂未开源)
Idea
目标实例之间的比例变化仍然是目标检测任务中的一个关键挑战,尽管现代检测模型取得了显著进展,但这一挑战在半监督的情况下尤为明显。
作者观察到具有极端规模的对象往往置信度较低,导致对这些对象缺乏积极的监督。
如下图所示,不合适的尺度会导致假阴性,这在半监督学习中,会误导学生网络。
总体来说其实就是印证了大型对象在深层特征图效果好,小型对象在浅层特征图效果好。

据此作者提出了混合尺度的特征金字塔,可以自适应的选择尺度来生成特征图,提出了PLM策略,挖掘有前途的伪标签。
Detail
Scale Variation Challenge
知识蒸馏(教师学生模型)应用在半监督领域的用法:
教师模型生成伪标签(软标签)和伪边界框,供学生模型训练。
为了保证高精度,大多数现有的半监督目标检测都采用严格的条件(如score>0.9)来过滤出高置信度的伪标签。
极端规模的对象往往具有低置信度,使得在这种半监督目标检测中遗漏。
[2022’CVPR]SED
2022年的CVPR中有一项工作叫SED,建议在常规视图+下采样视图之间蒸馏预测,来增强模型对尺度变化的鲁棒性。
这项工作证明结合未标记图像的额外下采样视图,并在特征级上使用一致性约束对网络进行正则化可以显著提高半监督目标检测的性能。
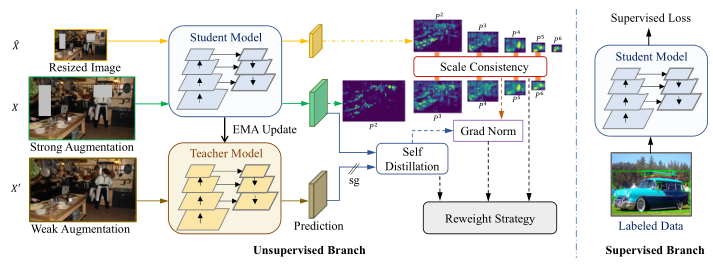
MixTeacher 网络结构
在训练过程中,模型首先使用特征提取模块(FPN)分别为常规视图和下采样视图构建特征金字塔,然后按比例构建混合金字塔
是sigmod激活,是做全局平均池化
教师这边只拿混合特征金字塔输入到检测头,得到的伪标签给学生训练,
然后学生在三个尺度上进行训练,检测头是权重共享的
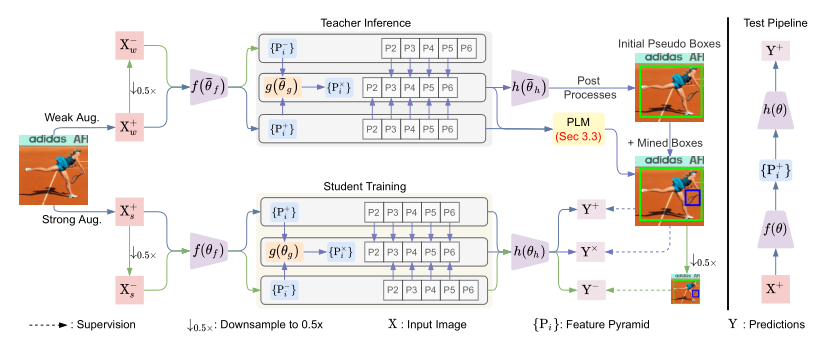
Promising Label Mining
作者提出了一个PLM(有前途的标签挖掘策略),来挖掘那些虽然低可信度但是有前途的标签。
只对分类得分最高的candidate使用:
作者定义了一个指标,来衡量从源视图到目标视图的平均得分的提升:
其实就是K个Proposal输入到分类头,得到的置信度分数之差,再取平均值。
额外给定义了一个晋升阈值,当大于这个阈值时,candidate会晋升为伪标签。
也就是说,这里只为分类损失挖掘伪标签,回归损失没有做相关工作(沿用2021’ICCV soft teacher作为baseline)
Result
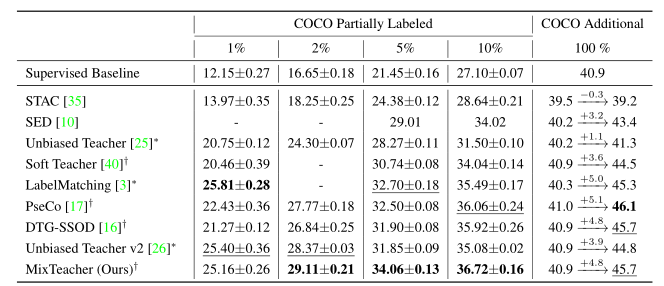
Baseline是Faster R-CNN, FPN,在coco数据集上的可以达到半监督的SOTA
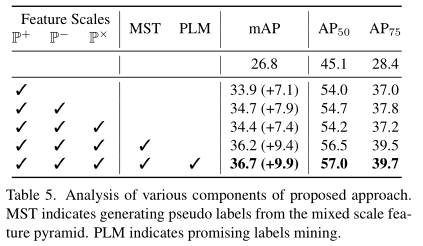
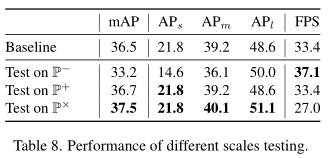
从它这个消融实验上看,好像这么直接相加的融合,除了推理速度会慢点,其它都是正面的(起码没有倒退)
总结
这种尺度变化在遥感图像数据集中还挺常见的。
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!