Cross-Head Knowledge Distillation for Dense Object Detection
CrossKD: Cross-Head Knowledge Distillation for Dense Object Detection
Introduction
论文题目 :CrossKD: Cross-Head Knowledge Distillation for Dense Object Detection
论文地址 :https://arxiv.org/pdf/2306.11369.pdf
论文出处 :In 2023 ’ ICCV (under review)
代码实现 :https://github.com/jbwang1997/CrossKD
Idea
目标检测知识蒸馏受到越来越多的关注,最近几年发现在目标检测领域中特征蒸馏(Feature Imitation)比逻辑蒸馏(Prediction Mimicking)更加高效一些。

作者发现GT和Distill Target(教师的预测输出)之间存在很大的差异,这一点一直都被之前的工作忽视了,然而作者认为这一点正是阻碍逻辑蒸馏Predicted Mimicking达到更高性能的原因。
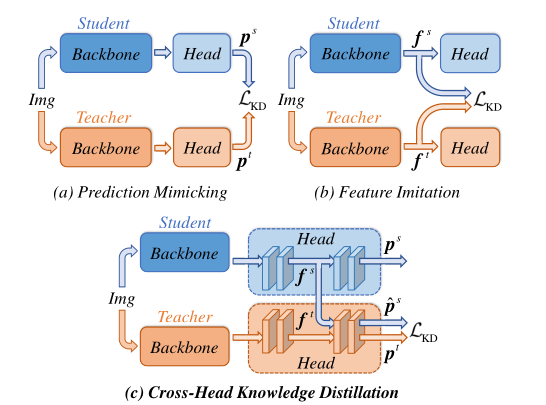
本文提出一种简单且有效的蒸馏机制CrossKD,它直接将Student Head的中间特征送入到Teacher Head,所得跨头(Cross-Head)预测将被用于最小化与老师模型预测的之间差异。这样的蒸馏机制缓解了Student Head从GT与Teacher Head预测处接收差异过大的信息,进而极大的改善了学生模型的检测性能。
看代码发现目前只适配了One-Stage的检测器,不知道Two-Stage检测器能不能work。
Detail
Cross-Head Knowledge Distillation
下图就是CrossKD的具体网络结构:
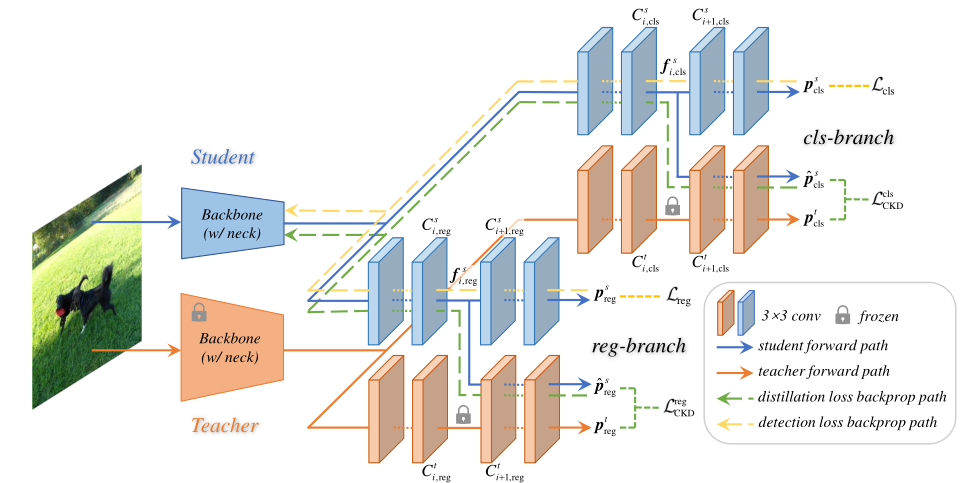
在分类分支和回归分支都采用了CrossKD,并且Cross的方案都是一样的
图上还画了反向传播的路径,Cross Head就是按原路径返回
要注意的是教师这边是已经训练好了的,所有参数都已经frozen固定住了,这也是为什么不进行反向传播
这个系数,在分类分支是1,在回归分支,前景部分是1,背景部分是0.
本质是CrossKD是一种逻辑蒸馏(Prediction Mimicking)
Optimization Objectives
训练的总损失就是检测损失和蒸馏损失的加权和:
Result
作者实验做的比较全, 这里也提一下:
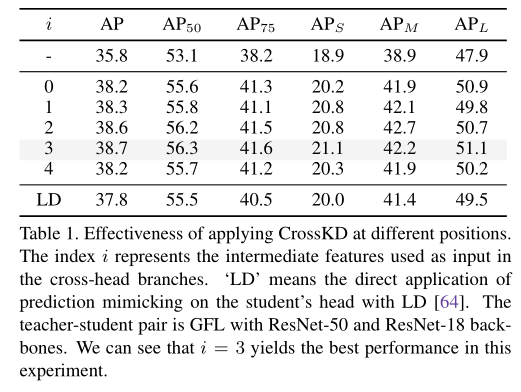
在RetinaNet上,实测第4层(i取3),也就是最后一个隐藏层效果最好:
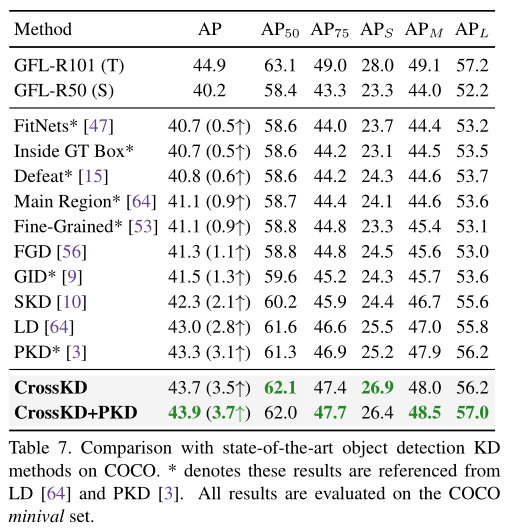
在coco minival集上,跟其它KD的精度对比,CKD(逻辑蒸馏)和PKD(特征蒸馏)叠加达到SOTA:
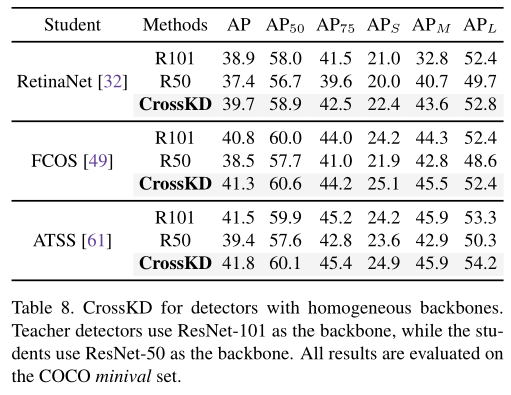
在coco minival集上,RetinaNet、FCOS、ATSS使用蒸馏,蒸馏后的学生模型精度超越单教师模型:
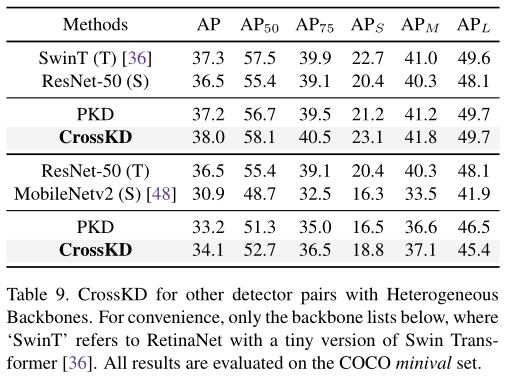
作者还实验了一些异构蒸馏,效果也不错:
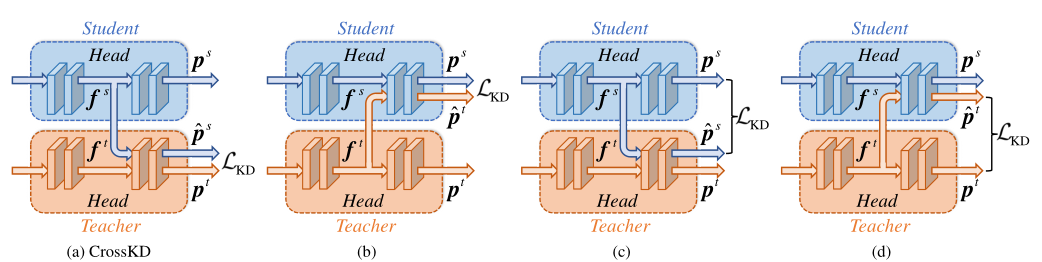
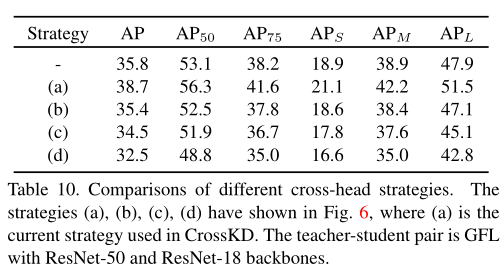
作者还实验了CrossKD的一些其它跨头方案组合,但这些其它方案都没有带来正面收益:
总结
目标检测知识蒸馏发展趋势:
首先是2017年的先驱工作:Learning efficient object detection model with knowledge distillation。
然后目标检测知识蒸馏收到越来越多的关注,最近几年发现在目标检测领域中特征蒸馏比逻辑蒸馏更加高效一些
一些工作侧重选择更高效的蒸馏区域进行更好的特征模仿;
一些工作设计损失函数,更好的衡量特征蒸馏损失;
一些工作设计新的师生一致性函数,旨在探索更多的一致性信息;
Typically,FGD使得师生注意力对齐,PKD使得特征表示之前的Pearson相关系数最大化.
其它
DOTA1.0数据集上的检测结果出来了:
| Model | .pth文件大小 | mAP(AP50) | AP75 |
|---|---|---|---|
| orpn_r50 | 330.4M | 75.904 | 50.452 |
| qpdet_r50 | 330.4M | 74.839 | 45.920 |
| orpn_r101_distill_r50_stu | 165.8M | 75.983 | 52.101 |
纯特征蒸馏的效果是最好的,但是提升精度也有限,模型大小倒是显著变小
特征蒸馏能直接和普通的模型进行对比么,遥感目前全监督知识蒸馏比较少,会不会有些不太公平?
可能只能画一个给不同网络架构蒸馏,然后精度提升的图…
欠缺出发点,欠缺可解释性
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!