Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detetion
Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detetion
Introduction
论文题目 :Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detetion
论文地址 :https://arxiv.org/pdf/2308.14286v1.pdf
论文出处 :2023’ICCV accepted
代码实现:https://github.com/TinyTigerPan/BCKD
Idea
在目标检测的分类分支中,使用Softmax激活函数得到K+1个分类置信度(K个前景和1个背景),由于目标检测任务中的前景背景极不平衡,因此大多数情况下会指向背景,这也是为什么logits蒸馏在目标检测中效果不佳的主要原因。
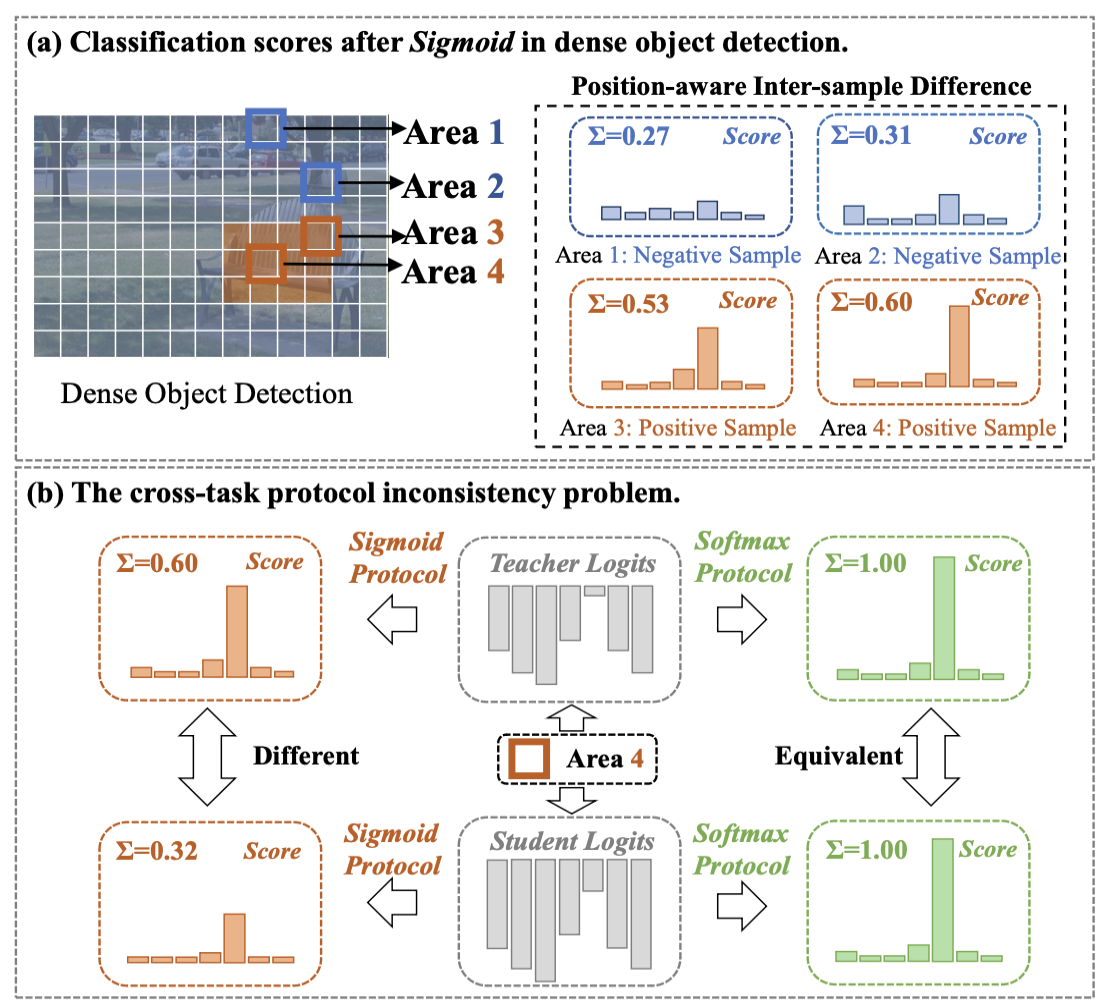
这个动机我理解的不是那么透彻
a) 目标检测中,正负样本(即前景背景)的分类得分之和存在差异
b) 当使用softmax激活函数的时候,尽管这个时候分类蒸馏损失为0,但是此时使用sigmod激活函数仍然存在不一致性
没有看懂为什么softma不行但是sigmod激活函数行,我分析可能是做k次独立的sigmod能包含更多信息?
我知道它在做什么以及怎么实现,但我没看明白它为啥要这样做
这里整篇文章把softmax和sigmod激活函数都称为任务协议(Protocol)。
Detail
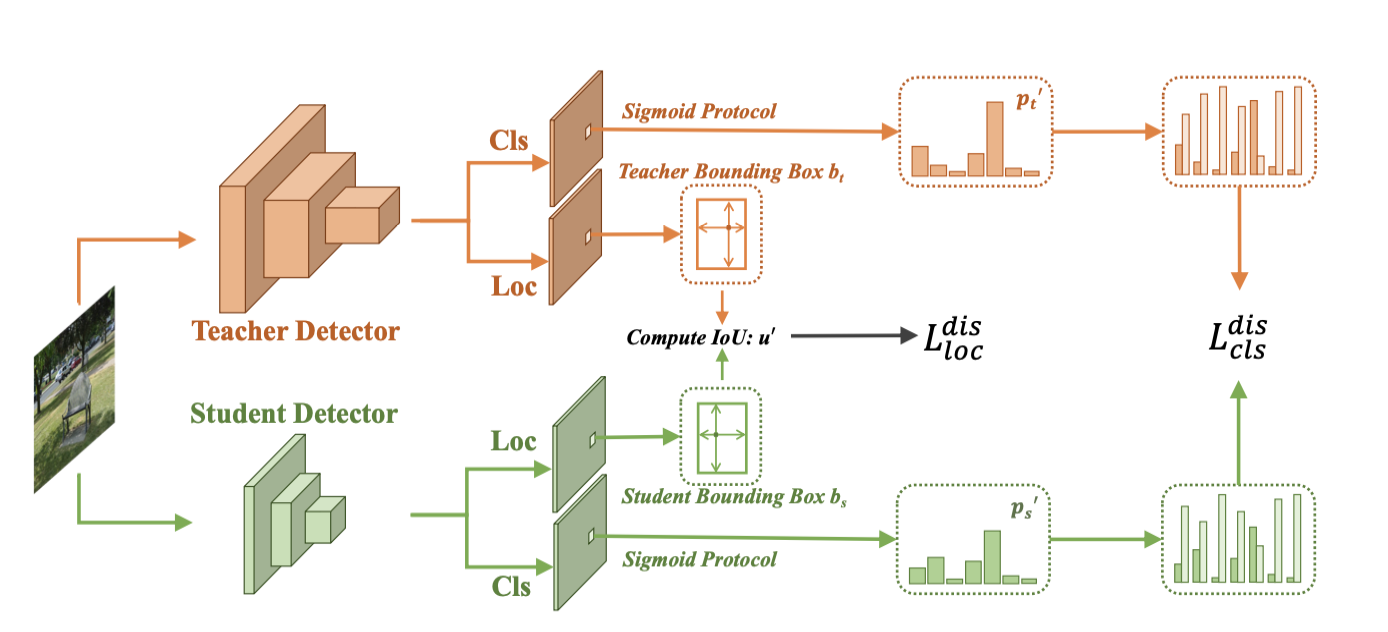
从框架结构图可以看出,它这里把分类分支和定位分支各做了一个蒸馏Loss,思路应该是来源于2022’CVPR的LD。
Classification Distillation Loss

因此,作者就打算做k次sigmod二分类
i,j 表示image中第i个位置,第j类
其权重,w的公式如下:
Localization Distillation Loss
在2022‘CVPR的LD中,LD在定位分支(Generalized Focal Loss Head)的做法是把bbox的每条边的位置通过softmax都range成一个概率分布,这样分类分支和定位分支都是概率分布logit知识蒸馏,使得两个分支任务统一。
这里作者认为要在定位分支特地加一个Generalized Focal Loss Head去做bbox的转换太复杂了,不具备通用性.
因此作者在定位分支就是把教师和学生输出的偏移量和,通过解码器decoder还原成预测框,然后计算教师预测框和学生预测框之间的IOU,记为,那么定位分支的Localization Distillation Loss可以定义为如下表达式:
Total Distillation Loss
总Loss就是以上两个Loss的加权,和是两个权重超参数。
Result
Classification Distillation Loss和Localization Distillation Loss广义上属于logit知识蒸馏,亮点就在于可以与目前一些feature知识蒸馏结合起来一起使用,效果更佳!
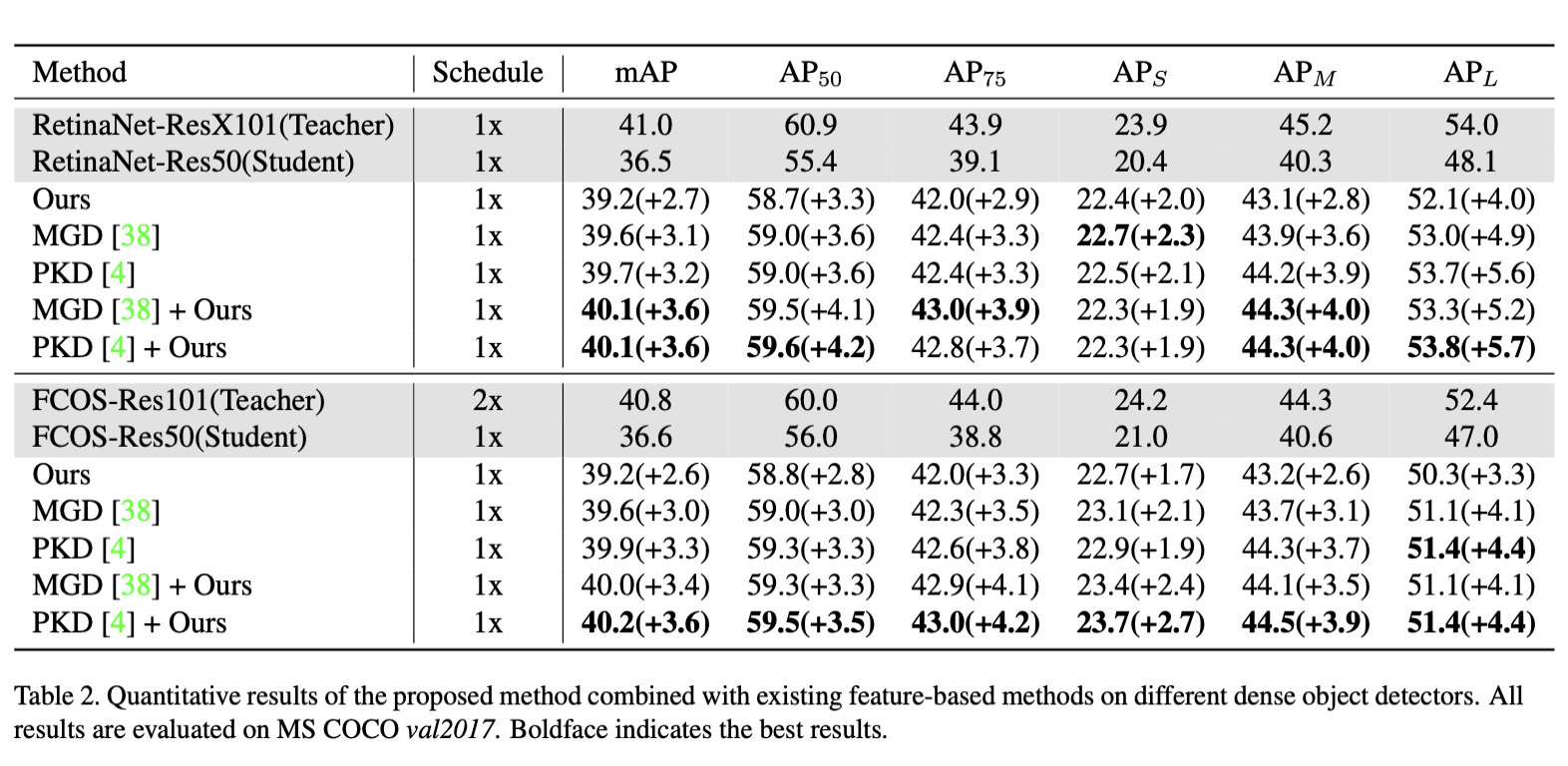
下图是一个跟LD对比的消融实验:
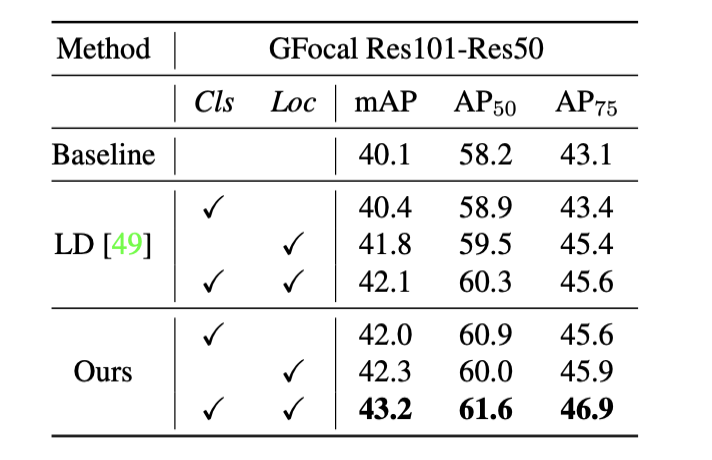
教师网络GFocal-Res101,学生网络GFocal-Res50,图中每个位置的分类得分的L1误差可视化:

总结
我觉得可以与feature知识蒸馏结合使用挺好的,对于旋转目标检测,在定位分支可以采用特殊的旋转IOU(如KFIoU)试试
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!