Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detetion
Spatial Transform Decouplling for Oriented Object Detection
Introduction
论文题目 :Spatial Transform Decouplling for Oriented Object Detection
论文地址 :https://arxiv.org/pdf/2308.10561v2.pdf
论文出处 :2024’AAAI accepted
代码实现:https://github.com/yuhongtian17/Spatial-Transform-Decoupling
Idea
作者提出了空间变换解耦,这里的解耦就是指对于不同语义含义的回归参数(对象的位置, 角度,大小),使用不同的网络分支(不同的Transformer Block Layer)来预测,以分而治之的方式有效的利用来ViT的空间变换潜力。在这样的解耦过程中,加入级联激活掩码来增强多个分支产生的特征,指导后续Self-Attenetion机制。
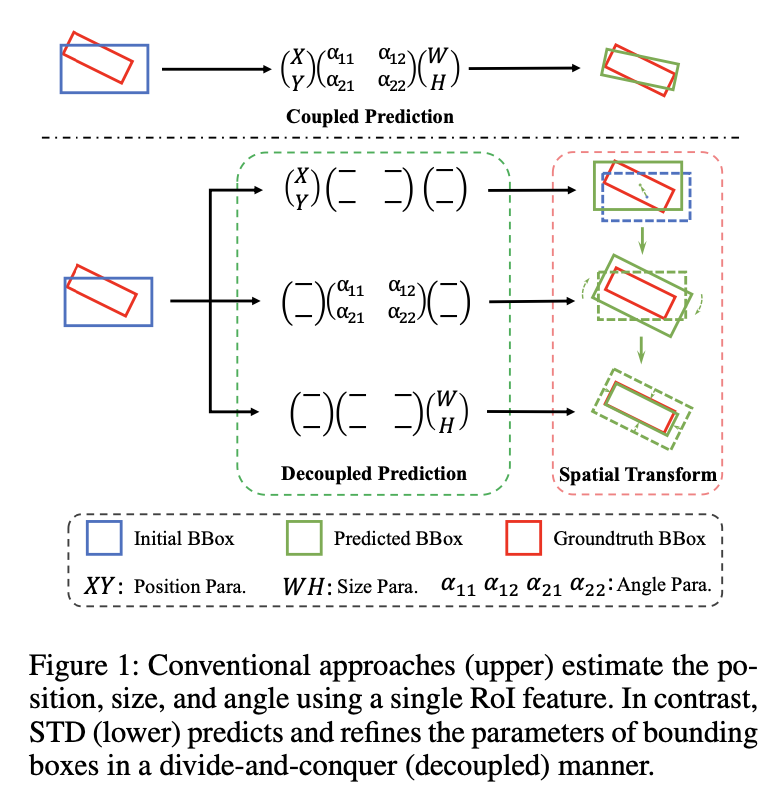
Detail
网络框架图
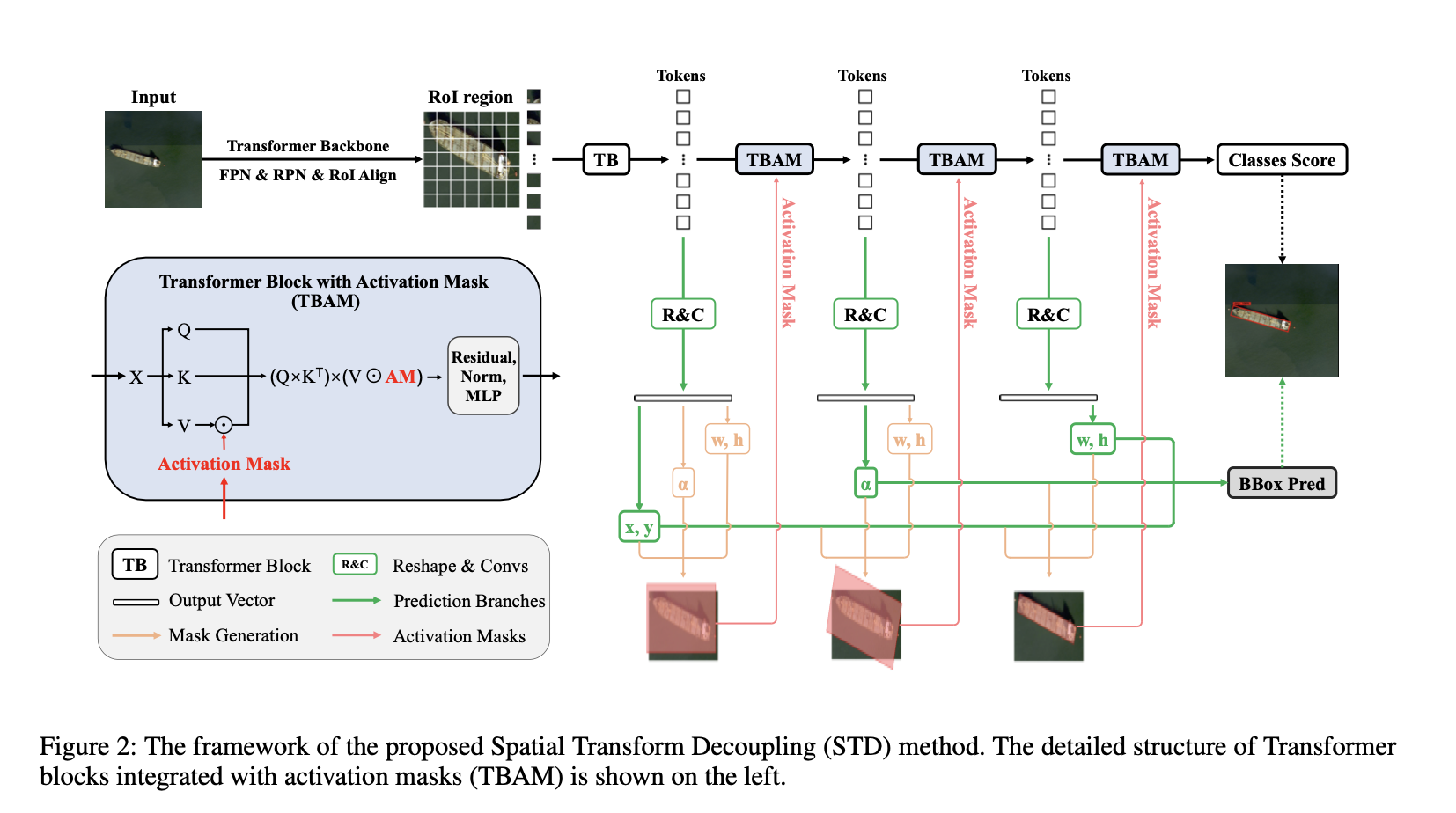
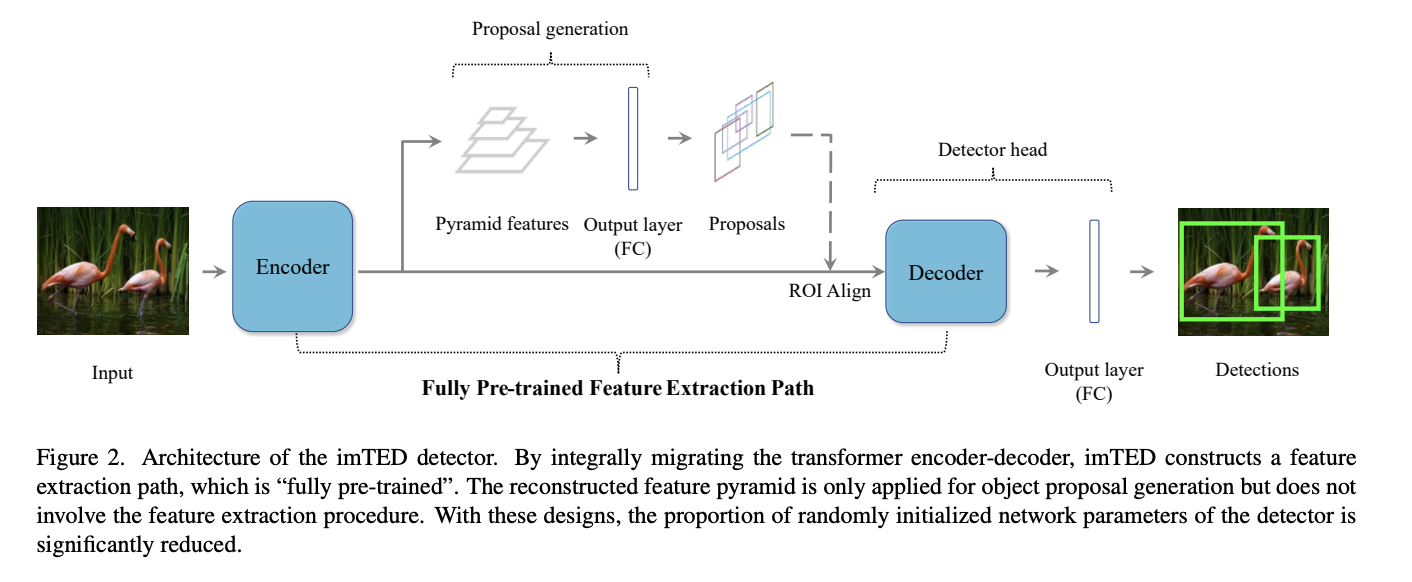
整体的网络架构参考的是imTED(2023’ ICCV),为了方便理解,这里简单介绍一下这篇文章:
imTED架构
一句话总结就是,将MAE预训练好的Encoder-Decoder整体迁移到目标检测中,比只迁移Encoder的方案性能↑,泛化性↑
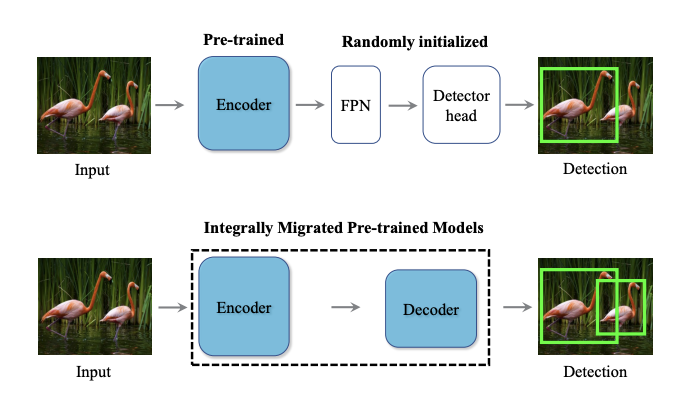
如果只是把原始预训练的Backbone迁移过去,对于检测头来说,参数都是随机初始化的
基于MAE预训练,在训练Backbone(Encoder)的同时,还会有一个Decoder,这个Decoder具有很强重构能力,于是作者就想着将整体的Encoder-Decoder做迁移。
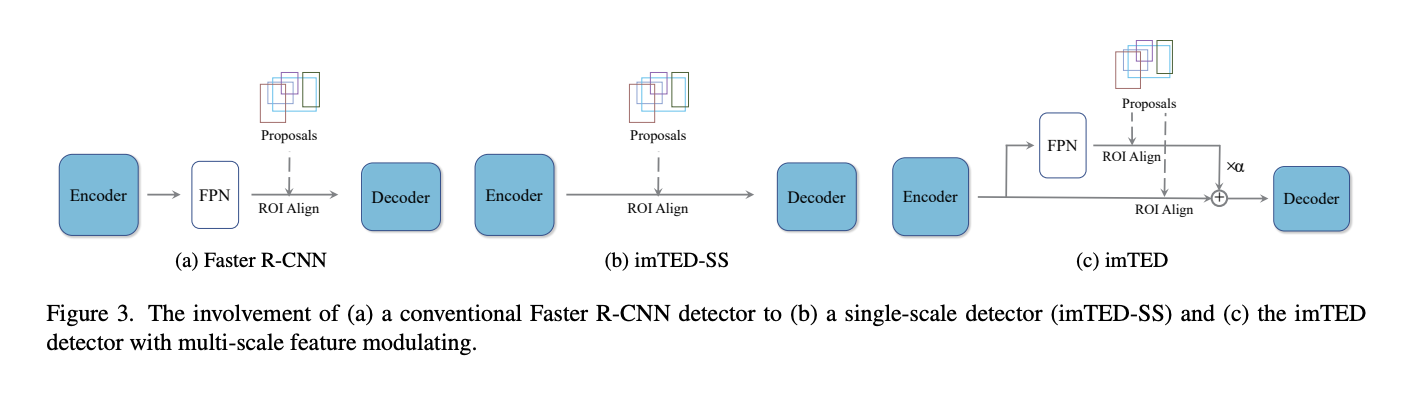
直接迁移方案会带来一个尴尬的局面,那就是在经过预训练的Encoder和Decoder之间有一个随机初始化的FPN,经过随机初始化的FPN处理的特征分布跟Encoder输出的特征分布肯定是不一样的,这样预训练的Decoder的功能就要大打折扣了。为了构建一个跟预训练时一致的特征流,作者取Encoder的最后一层的特征输入到Decoder中,如图(b)所示。
作者额外提出了一个多尺度调制器,整体分两组进行,一组对Encoder最后一层的特征进行,另一组对FPN输出的多尺度特征进行,然后以learnable的方式将这两个特征组合后送入到Decoder中,公式如下所示:
整体的迁移架构如下所示:
对比上面两张网络框架图,STD就是把二阶段RoI Align后的全连接层替换成了4层Transformer Block。
这里Backbones使用的是基于MAE预训练的ViT-Small
参数解耦预测
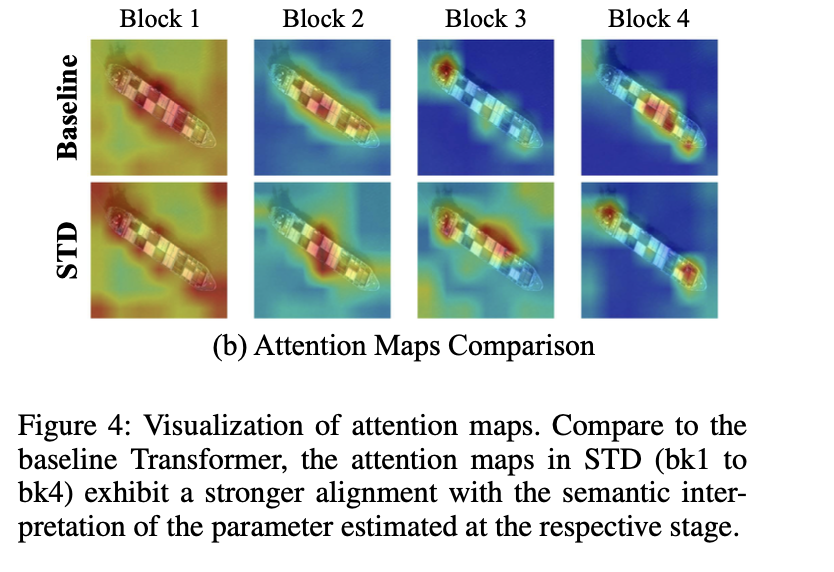
对象的位置, 角度,大小和类别得分(cls score)分别是根据第1、2、3、4层的Transfomrer Block预测得到的。
具体来讲,在得到每个Transformer Block的离散token输出后,把它重构为7×7的特征图(与RoI Align后的特征图大小一致)
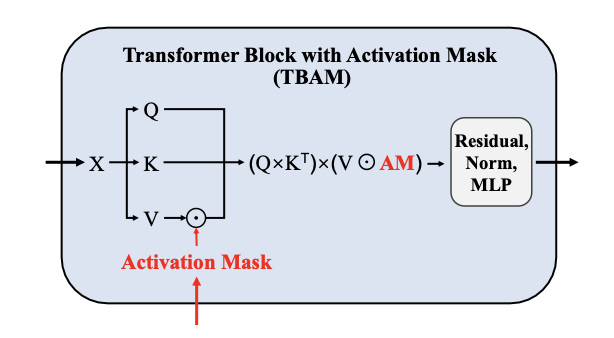
级联激活掩码
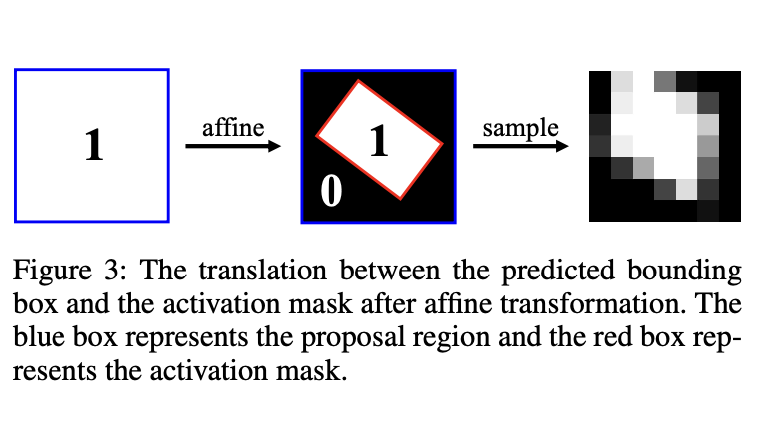
就是一个根据proposal生成的二进制掩码,用来增强前景特征的。
这个掩码后续用来跟V进行点乘操作,以指导自注意力机制。
Result
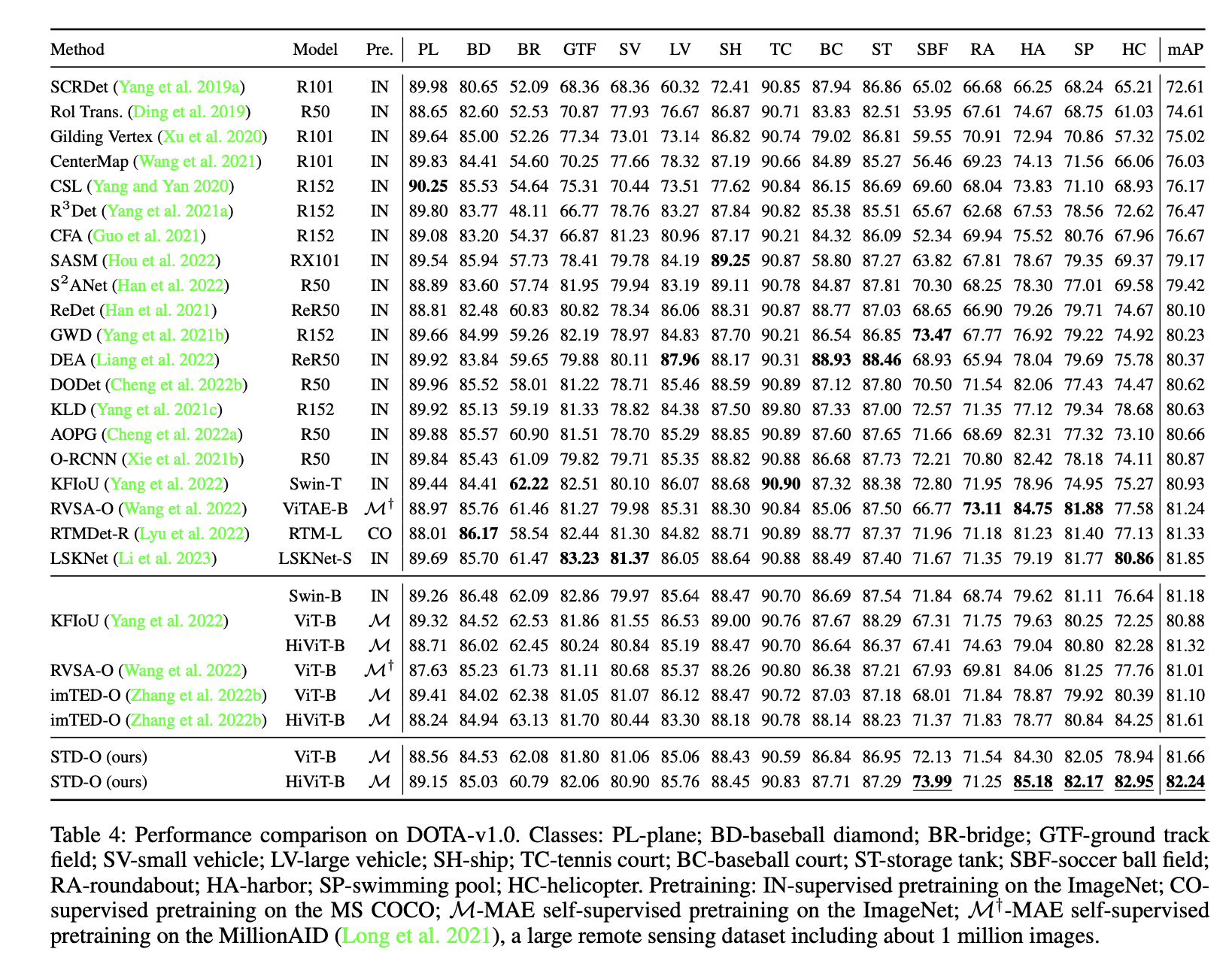
DOTA1.0数据集上的性能,SOTA:
消融实验,做了不解耦预测参数,和解耦参数的顺序:

本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!