Heterogeneous Architectures in Knowledge Distillation
One-for-All: Bridge the Gap Between Heterogeneous Architectures in Knowledge Distillation
Introduction
论文题目 :One-for-All: Bridge the Gap Between Heterogeneous Architectures in Knowledge Distillation
论文地址 :https://arxiv.org/pdf/2310.194441v1.pdf
论文出处 :arXiv
代码实现:https://github.com/Hao840/OFAKD.
Idea
现有的知识蒸馏相关研究只考虑了同架构模型的蒸馏方法,而忽路了教师模型与学生模型异构的情形。例如,最先进的MLP模型在lmageNet上仅能达到83%的精度,无法获取精度更高的同架构教师模型以使用知识蒸馏方法进一步提高MLP模型的精度。因此,对异构模型知识蒸馏的研究具有实际应用意义。
Detail
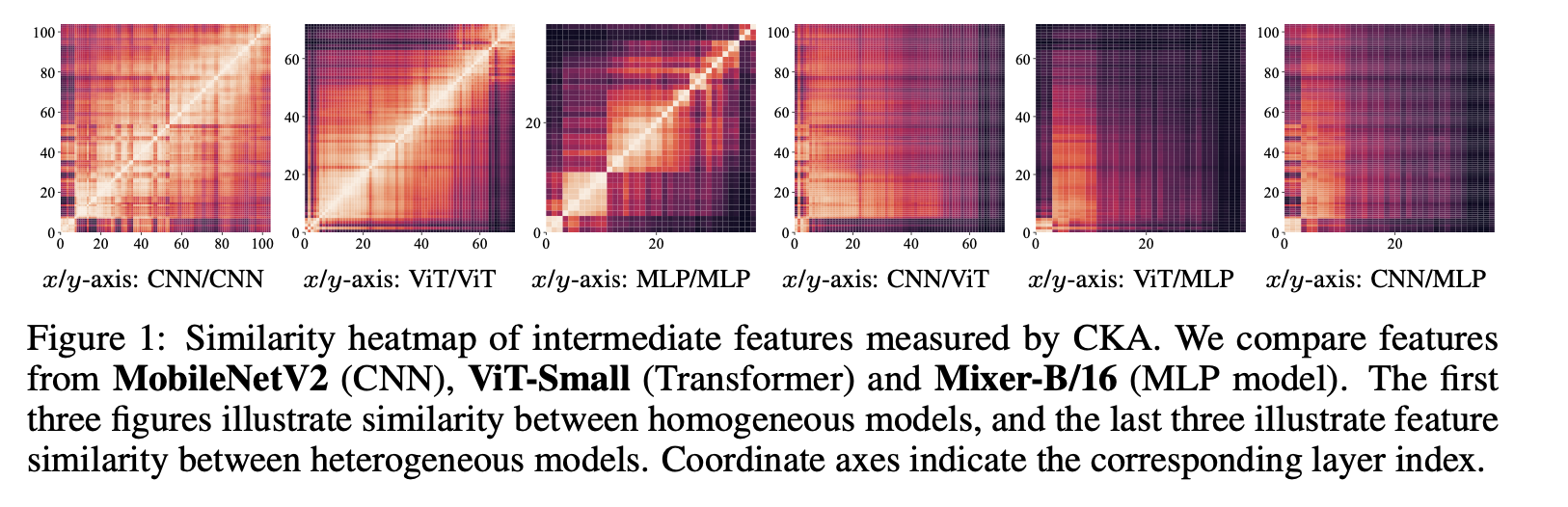
用CKA 测量的中间特征的相似度热图,前三幅图说明了同构模型之间的相似性,后三幅图说明了异构模型之间的特征相似性。

model

借鉴了early-exit model architecture,教师模型分离出对应的中间层loss
我们将中间特征投影到对齐的潜在空间(例如 logits 空间)中,其中特定于架构的信息被丢弃
result
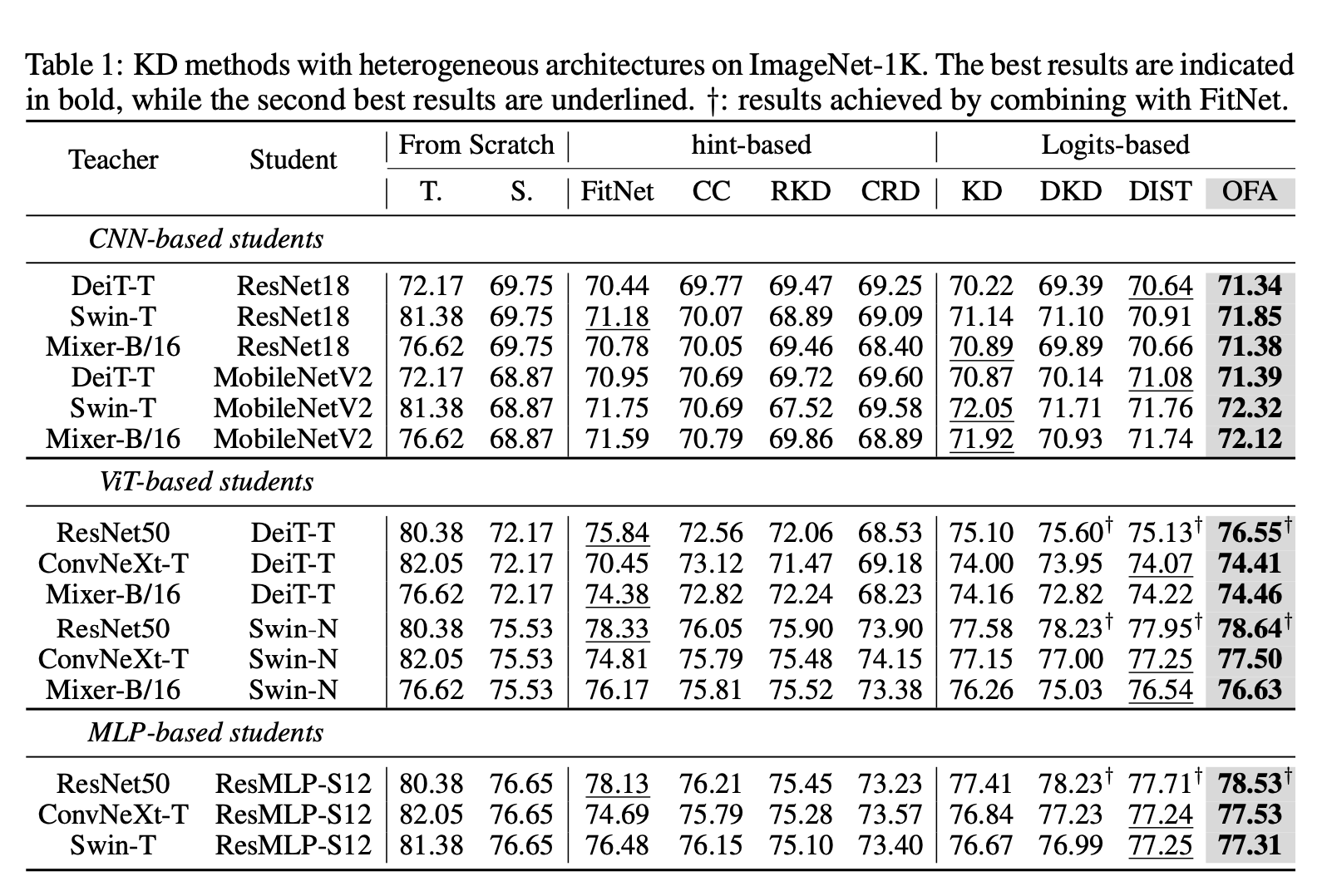
比较的方法都是一些比较老的方法(2021年及以前)
PKD
论文题目 :PKD: General Distillation Framework for Object Detectors via Pearson Correlation Coefficient
论文地址 :https://arxiv.org/pdf/2207.02039.pdf
论文出处 :2022‘ NIPS
代码实现 :https://github.com/open-mmlab/mmrazor
作者根据经验发现,来自异构的教师检测器的能生成更好的FPN特征来帮助学生,但是是异构的主要问题是feature的尺度差距太大,会带来强约束和noise,不利于student学习。所以干脆就对FPN的feature map做normalization(减均值,除方差),然后求均值方差MSE好了。
Detail
教师和学生的特征值大小不同,尤其是对于异构检测器。因此直接对齐之间的特征图老师和学生可能会施加过于严格的约束,从而不利于学生的学习。
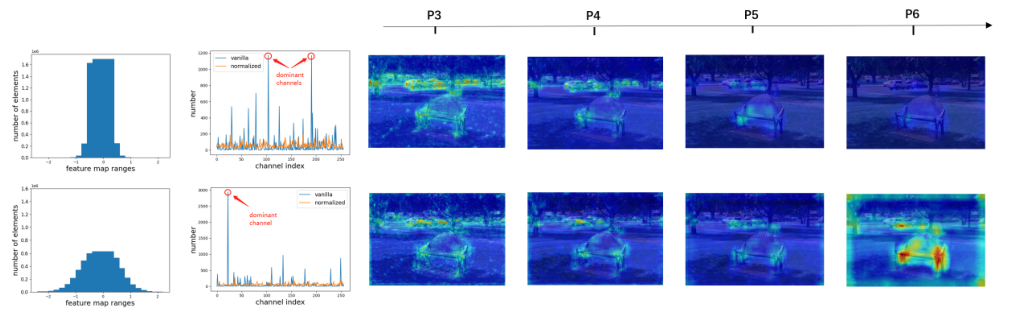
这张图第一行是Teacher,第二行是Student。
第一张图是特征图大小的分布,,如图 1(左)所示。
右边做的是可视化,很明显FPN Layer 6的相似程度小于Layer 3。
不光是图像的宽高,某些通道中的像素值显着比其他通道中的通道大,这些像素可能是噪音。
因此,直接模仿特征图可能会引入很多噪声。
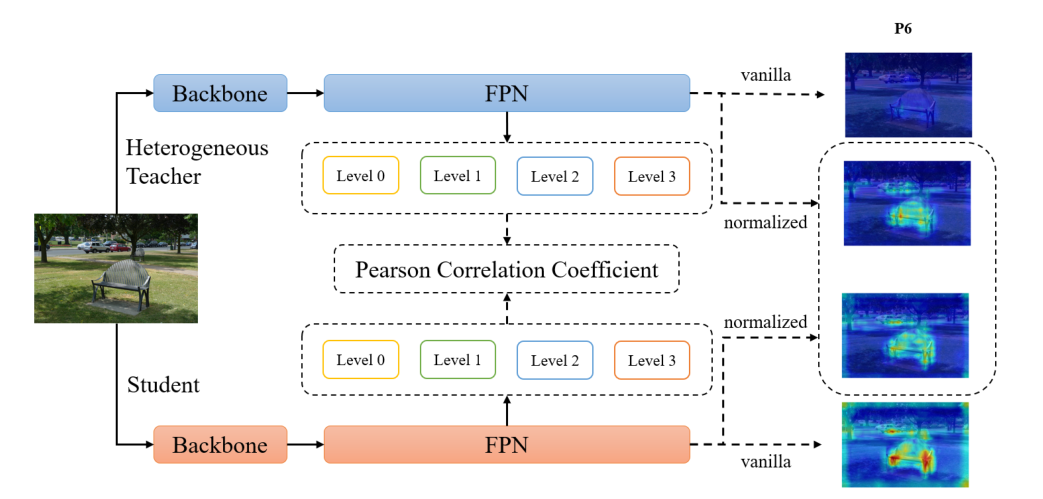
后面就打算改用皮尔逊系数蒸馏
作者证明了一下,这么做等价于算两者的皮尔逊相关系数.

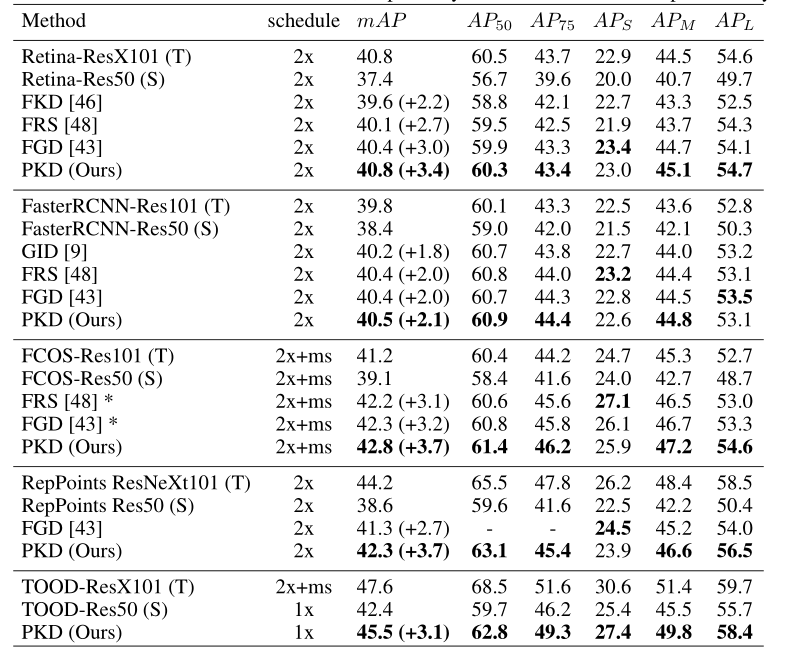
Result
在coco数据集上测试简单但是有效
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!