Knowledge Distillation- Unified Approach with Normalized Loss and Customized Soft Labels
From Knowledge Distillation to Self-Knowledge Distillation: A Unified Approach with Normalized Loss and Customized Soft Labels
Introduction
论文题目 :从蒸馏到自蒸馏:通用归一化损失与定制软标签
论文地址 :https://arxiv.org/pdf/2303.13005.pdf
论文出处 :ICCV 2023
代码实现:https://github.com/yzd-v/cls_KD
Idea
原生蒸馏使用教师的logits作为软标签,与学生的输出计算蒸馏损失。自蒸馏则试图在缺乏教师模型的条件下,通过设计的额外分支或者特殊的分布来获得软标签,再与学生的输出计算蒸馏损失。二者的差异在于获得软标签的方式不同。
这篇文章旨在,1)改进计算蒸馏损失的方法,使得学生能更好地使用软标签。2)提出一种通用的高效简单的方法获得更好的软标签,用于提升自蒸馏的性能和通用性。针对这两个目标,作者分别提出了Normalized KD(NKD)和Universal Self-Knowledge Distillation (USKD)。
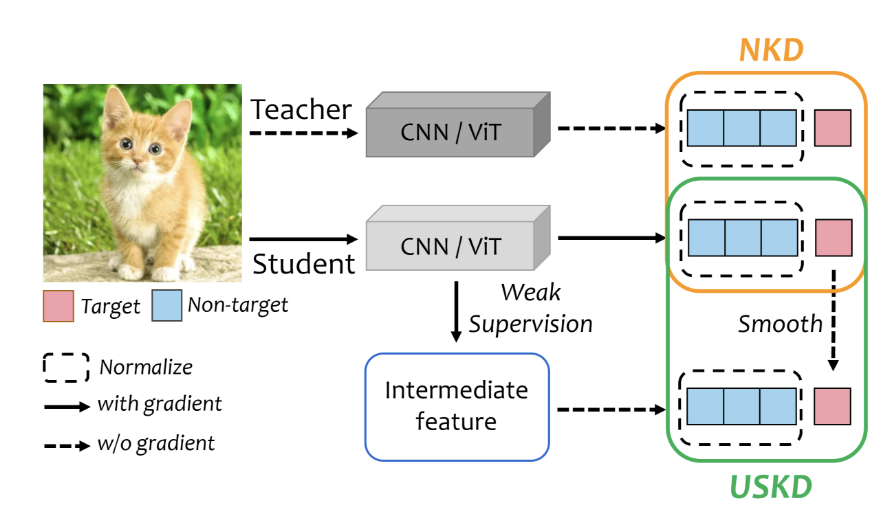
Detail
对于以下公式:用表示目标类别,表示类的数量,表示每个类的标签值,表示学生输出的标签概率,表示教师输出的标签概率。
对于图像分类任务,它原始的损失函数是使用交叉墒计算:
添加了教室学生网络后,教师输出soft label,与学生进行逻辑蒸馏:
蒸馏损失的第一项和模型原损失一致,均是关于目标类别target。而蒸馏损失的第二项则是交叉熵的形式,交叉熵损失的优化目标是使与接近,观察蒸馏损失的第二项可知, , 。在训练中,学生输出的目标类别概率是在不断变化的,无法恰好与相等,这使得两个non-target logits的和不等,阻碍了 与 变得接近。因此作者针对两个non-target logits进行归一化,强制使他们相等,提出了Normalized KD, 用于更好地使用软标签:
Result
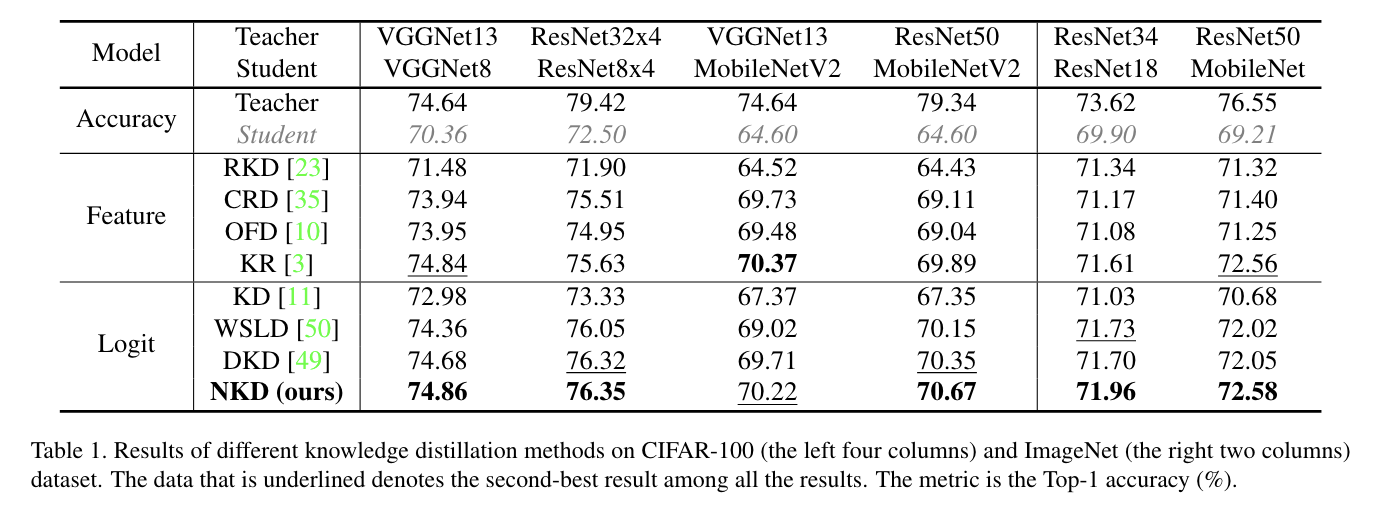
在cifar-100数据集上做测试:
总结
个人理解:
原始的分解为target和non-target证明了中的non-target项与存在冲突,进行归一化是为了减少损失函数中non-target项对优化方向的影响,使总损失+更偏向target.
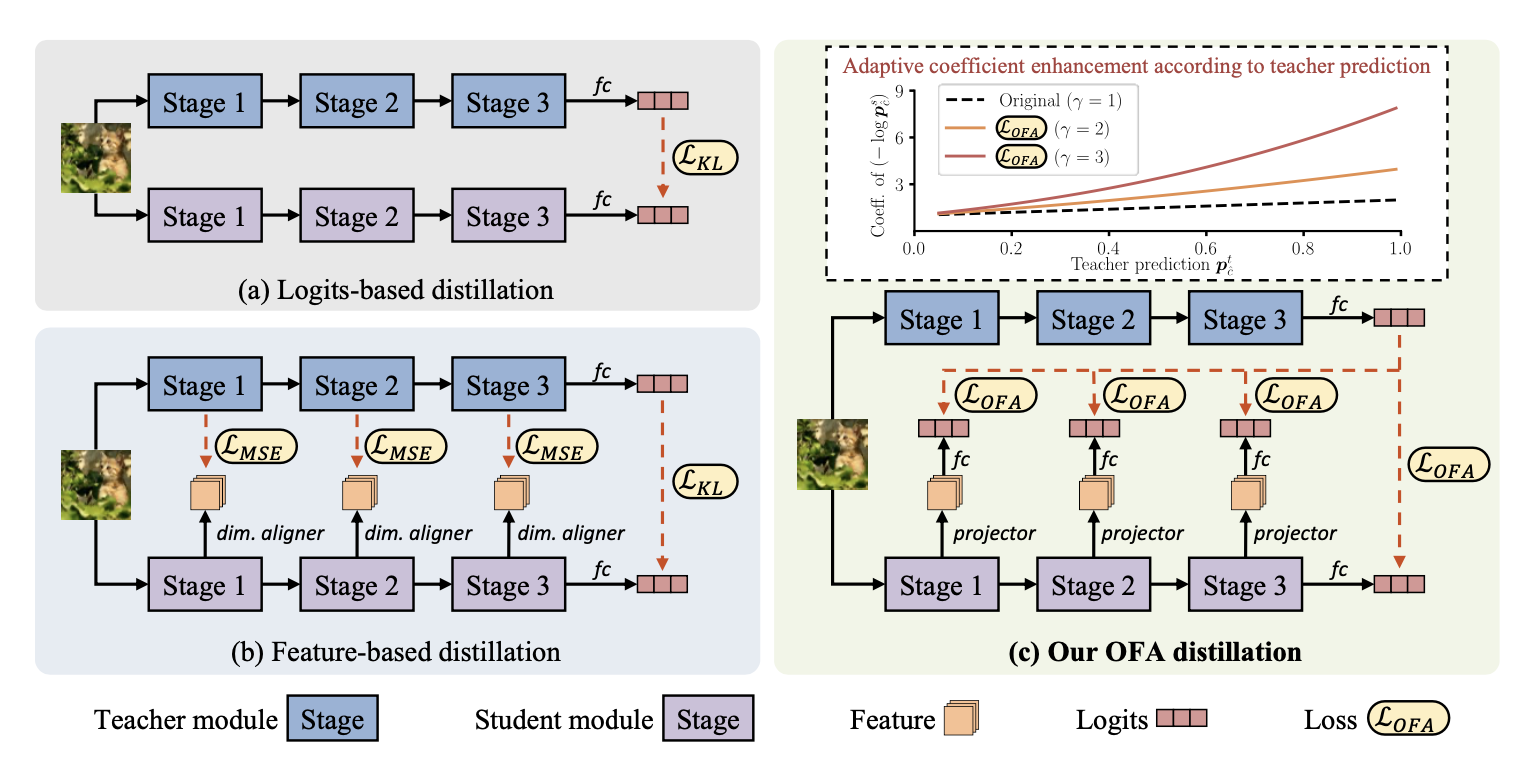
这篇文章相当于是提出了一种对logit蒸馏的优化方式,我觉得可以跟之前看的OFAKD结合起来看:
OFAKD通过将学生模型的中间层特征映射到logits空间,实现对模型架构相关信息的过滤,从而专注于任务相关信息的传递。(通过将学生模型的特征映射到与教师模型对齐的统一空间)
本博客所有文章均采用 CC BY-NC-SA 4.0 协议 ,禁止商用,转载请注明出处!